李瑞松,刘洪久,胡彦蓉
(浙江农林大学 数学与计算机科学学院,浙江 杭州 311300)
“富裕”是社会生产力发展水平的集中体现,是反映社会对所有财富共同拥有的行为情况;“共同”则是社会生产力性质的具体表征,反映社会成员对财产共同占有的行为方式。因此,共同富裕包括了生产力和生产关系两个方面的共同特征,可以成为评价一个国家或社会、社会成员对财产占有方式和程度水平的重要尺度[1]。共同富裕思想是马克思主义理论体系的重要内容,实现共同富裕是社会主义的本质要求,更是中国共产党的奋斗目标与初心使命[2]。中华人民共和国成立以来,共同富裕成为观察现代中国的重要价值与事实。邓小平同志提出了“一部分地区、一部分人可以先富起来”“先富起来的地区和人带动和帮助其他地区、其他的人,逐步达到共同富裕”的路径[3]。进入新时代,党把共同富裕提升为国家战略,通过精准扶贫等重大举措解决当代中国的贫困问题[4]。党的十九届五中全会明确了扎实推动共同富裕的目标要求,但如何从理论维度评价和衡量这一目标进度是亟待研究的课题。《中共中央国务院关于支持浙江高质量发展建设共同富裕示范区的意见》中指出,要加快构建推动共同富裕的综合评价体系,研究方法上要坚持定量与定性、客观评价与主观评价相结合,内容上要全面反映示范区工作成效,以及人民群众的满意度和认同感[5]。党的十九届六中全会再次提及共同富裕的问题,指出要把实现高质量的发展和体现效率、促进公平收入分配格局作为实现共同富裕的路径,为新时代推进共同富裕指明了方向。深刻理解新时代共同富裕的科学意蕴,对于持续深入推进社会主义现代化强国的建设意义重大[6]。科技部网站于2022年1月25日发布了科技部、浙江省人民政府关于印发《推动高质量发展建设共同富裕示范区科技创新行动方案》的通知,文件围绕打造支撑城乡区域协调发展的全域创新范例、树立科技赋能民生改善的领先标杆、夯实创新驱动高质量发展的内生动力、构建高标准技术要素市场示范区四个方面提出相应举措。习近平总书记在党的二十大报告中明确指出:“中国式现代化……是全体人民共同富裕的现代化。”(1)习近平:《高举中国特色社会主义伟大旗帜为全面建设社会主义现代化国家而团结奋斗——在中国共产党第二十次全国代表大会上的报告》,北京:人民出版社,2022年。实现全体人民共同富裕是中国现代化建设的一个核心议程,必须一以贯之[7]。
有关学者对于共同富裕的研究包括:(1)共同富裕生成逻辑、科学内涵和实践路径的研究;(2)共同富裕的评价研究。刘洪森从新时代共同富裕的思想资源、新时代共同富裕的历史条件、新时代共同富裕的现实基础三个方面系统地阐述了新时代共同富裕的生成逻辑是马克思主义与中华优秀传统文化的思想资源,党领导人民进行革命、建设、改革的历史条件,以及中国特色社会主义新时代伟大成就的现实基础的有机统一;新时代共同富裕的科学内涵不仅体现在社会主义的本质要求、中国式现代化的重要特征上,还体现在全体人民共同富裕和非整齐划一的平均主义等方面[3]。共同富裕战略已成为党和国家重大的政治举措,并通过精准扶贫等系列政策来落实,以实现人民国家、民族国家、政党国家三种国家形态的同构共生[4]。刘旭雯指出:“推动共同富裕取得更为明显的实质性进展”既是对过去中国共产党推动共同富裕实践积极探索的认可,也是新时代对实现共同富裕提出的新任务和新目标,表明推动共同富裕是中国共产党建设社会主义现代化国家的核心要义[6]。江畅等人从哲学的角度把共同富裕作为奋斗目标的根本,其合理性解释为:实现共同富裕不是要“均贫富”,剥夺富裕者,而是要使全体社会成员都成为富裕者,获得自由而全面的发展[8]。周文等学者从政治经济学的角度对共同富裕进行了辩证分析,结果显示,共同富裕是生产与分配的有机结合、是市场与政府的有机结合、更是阶段性目标与最终目标的有机结合,而不是同步富裕[9]。与此同时,结合刘洪森和王娟等人最新研究成果可以得出[3,10],相关学者将共同富裕的实践路径概括为四点:一是坚持党的领导,提高党带领人民实现共同富裕的本领;二是推进高质量发展,满足人民对美好生活的需求;三是坚持社会主义基本经济制度,有序推进共同富裕;四是促进人民精神生活共同富裕,实现物质富裕和精神富裕的统一。
共同富裕的评价研究可细分为评价指标选取与评价方法研究。评价指标选取的研究现状如下:宋群从覆盖基础评价指标、核心评价指标、辅助评价指标三个方面选取了23个指标。其中,基础评价指标由覆盖经济、社会、文化、生态及制度五个方面的15个指标组成;核心评价指标由反映收入差距、地区差距与社会保障三个方面的6个指标组成[1]。蒋永穆等学者依据涵盖人民性、共享性、发展性、安全性四个方面的评价体系设置了14个评价指标,作为扎实推动共同富裕的评价指标[5]。史琳琰等学者提到了指标评价与选取,分别从高质量发展和发展成果共享两方面进行,结果表明居民共享发展成果与高质量发展表现出较强的内在一致性和发展协同性[11]。不过上述学者只是从理论上对共同富裕的评价指标进行了探索,并没有真正从现实数据上获取评价指标。此外,目前对于共同富裕评价方法的研究相对较少,大多数研究只是对于共同富裕评价体系的探索,从全国各个省份共同富裕的差异性和共同富裕程度分类预测的研究更是少之又少。史琳琰等学者利用因子分析法确定每一级指标的权重大小,再运用加权计算的方法得到历年居民共享发展成果得分[11]。李艳等学者基于共同富裕的视角,对2011—2020年的浙江省城乡融合发展水平进行了测度与分析[12]。本文参考《全国地市州盟相对富裕程度与统筹发展监测评价报告》,尝试将全国31个省份(除港澳台外)的共同富裕水平按照A+级、A级、A-级、B级,共划分为四个等级进行分析研究,这样可以横向地呈现出全国东西部地区的均衡发展水平[13]。同时,本文参照相关研究成果,选取2013—2020年时间跨度进行纵向的对比研究,研究结果可将中国近年来省际共同富裕水平的测度情况形象地展现出来[11-16]。
伴随机器学习的快速发展,深度学习方法的优势在各个领域的研究中均有显现[17-23]。张志恒等学者运用PCA-BP神经网络对审计风险进行识别预测,利用主成分分析方法(PCA)对数据进行精简和降维处理再输入到神经网络模型,有效地提升了模型的识别效率,识别准确率平均可达90.04%[17]。朱伟等学者以信阳市为研究区域,通过建立评价指标体系并使用PCA的打分方法完成了城市宜居性评价的实证研究[18]。林伟铭等学者提出了一种基于主成分分析与极限学习机模型相结合的阿尔茨海默病辅助诊断方法,研究结果表明,该方法在阿尔茨海默病的诊断上有较高准确度,其准确率达到95.1%,比常规方法提升3.5%[19]。综上可以看出,PCA评价方法具有较高的准确性和广泛的应用性,因此本研究选取PCA评价方法进行中国共同富裕水平综合打分。此外,K均值聚类方法相对于其他几种聚类方法更易学习与运用[20-21]。于是本研究采用K均值聚类方法进行中国共同富裕等级的划分。卷积神经网络(CNN)模型在图像分类领域的应用已十分成熟,在医学领域可准确地区分良恶性结节[22]。同时,相关学者将CNN模型应用于雷达信号的特征提取与预测分类,实验效果对比传统模型有较明显提升,其分类准确率最高可达97.17%[23]。由此可见,CNN在多分类问题上表现出高效的作用。基于CNN模型在多分类问题上高效的特性,本研究将运用该模型对中国省际共同富裕程度进行预测分类。
综上,基于国内外缺少对中国省际间共同富裕的差异性、共同富裕程度评价及分类预测的相关研究这一现状,结合主成分分析法(PCA)与卷积神经网络(CNN)各自的优越性,本研究尝试将主成分分析法(PCA)与卷积神经网络(CNN)构成组合模型用来衡量中国省际共同富裕水平并提取主要特征进行预测分类,将卷积神经网络模型应用于一维数据的分类与回归。首先,这一研究可实现将中国近年来为缩小贫富差异和推动城乡发展所取得的工作成果形象地展示出来。同时,这也是将传统方法与深度学习方法相结合应用于中国省际共同富裕水平的画像,以数据的方式将中国近年来各个省份共同富裕的发展状况呈现出来,对于推动均衡发展生产力,消除两极分化具有一定的现实意义。其次,这一研究对于进一步推动全国共同富裕进程具有借鉴意义。最后,本文在现有研究[24-29]的基础上,还提出了几点关于推动中国共同富裕进程的建议。
(一)数据来源与指标体系的构建
1.数据来源
考虑数据的合理性与可得性,研究数据来源于国家统计局《中国统计年鉴》中2013—2020年的31个省份(不包含香港、澳门和台湾)的相关数据,通过手动整理和导出的方法进行获取。
2.指标体系的构建
指标体系的构建依据《中共中央国务院关于支持浙江高质量发展建设共同富裕示范区的意见》中提到的“到2025年,浙江省推动高质量发展建设共同富裕示范区取得明显实质性进展。经济发展质量效益明显提高,人均地区生产总值达到中等发达经济体水平,基本公共服务实现均等化;城乡区域发展差距、城乡居民收入和生活水平差距持续缩小,低收入群体增收能力和社会福利水平明显提升,以中等收入群体为主体的橄榄型社会结构基本形成,全省居民生活品质迈上新台阶;国民素质和社会文明程度达到新高度,美丽浙江建设取得新成效,治理能力明显提升,人民生活更加美好。”(2)《中共中央国务院关于支持浙江高质量发展建设共同富裕示范区的意见》,http:∥www.gov.cn/zhengce/2021-06/10/content_5616833.htm,访问日期:2022年6月20日。这一发展目标,可以归结为以下五点:一是提升经济发展水平;二是缩小人民收入和消费水平差距;三是完善社会保障体系;四是重视人民文化生活建设;五是提升生态环境治理水平。
相关学者对于共同富裕内涵的初步探索而建立的评价指标体系,从经济发展、社会发展、收入消费、文化发展及生态环境5个方面进行选取[1-5,9-12]。其中“富裕”层面的测度,周文等学者提到“富裕”要求社会生产力高度发展,这种生产力水平需要效率才能够实现[9]。由此可知,“富裕”层面的度量可以从体现生产力发展和人民生活水平状况的指标进行选取,本文选取地区生产总值和当地居民人均可支配收入来进行衡量。
经济发展不单一指国民经济规模的扩大,更象征着经济和社会生活素质的提高。经济发展层面可从地区生产总值、研究与试验发展(R&D)经费投入情况、城镇化进程、第三产业增长等方面进行指标的选取。
社会发展包括个体的物质发展、精神发展上升到社会层面,并取得社会化的一致认可。这其中包含经济、文化、政治、习俗、体制等一系列社会总体发展状况。社会发展层面的评价,可从居民受教育程度、基础设施覆盖情况等进行指标选取。
消费是社会再生产的重要环节,也是最后一个环节。党的十九大报告提出要“完善促进消费的体制机制,增强消费对经济发展的基础性作用”,这不仅要求从体制与机制的高度解决居民消费能力欠缺的问题,而且首次强调了消费的本质性作用[30]。收入消费层面的评价,可从恩格尔系数、居民人均可支配收入、城乡居民收入比等方面进行指标选取。
文化是综合国力的重要组成部分,也是增强综合国力的重要力量。丰富健康的文化生活是衡量人们生活质量的显著标志。改革开放以来,中国经济社会长足发展,人们对精神文化生活提出了新的要求,不仅给文化建设注入了新的动力,也使得精神文化产品的生产与人民群众日益增长的精神文化需求之间的矛盾更加突出。坚持以人为本,优化文化建设,不断满足人民群众日益增长的多层次精神文化需求,推动人的全面发展,已成为中国现代化建设的一项重大而紧迫的任务。文化发展层面的测度,可结合居民幸福程度和文化娱乐情况进行指标选取。
生态环境是指同人们生活息息相关的、直接影响着人们生活和生产活动的所有天然动力、自然作用的总和。习近平总书记指出,良好生态环境是最公平的公共商品,是最普遍的人民福利。这其实就是强调要从人民生活改善和民众幸福的视角,去改造好生态环境。可以说,生态环境质量直接决定了人民生活质量,改善生态环境就是提高民生,而损坏生态环境就是损害民生。因此,应该使广大人民群众在良好的生态环境中生活,并使良好的生态环境变成人民群众生命质量的新增长点。对于生态环境方面的测度,可以在环境质量评估方面进行指标的选择。
结合实际情况并排除相似指标对分类预测的干扰,从《中国统计年鉴》现有可获取到的指标数据和通过公式计算得出的途径共选取了14个指标。其中2013年、2014年的个别省份部分指标数据缺失,本研究通过计算取平均值得出。指标体系如表1所示。
其中,相关指标的含义与基本概念阐述如下:
(1)经济发展指标(4个)
地区生产总值GDP:地区生产总值GDP是按市场价格计算的一个地区所有常住单位在一定时期内生产活动的最终成果,可以有效地评价一个地区的经济状况。在本研究中,通过计算地区生产总值GDP的多少来衡量中国31个省份的经济水平和人民生活质量情况。
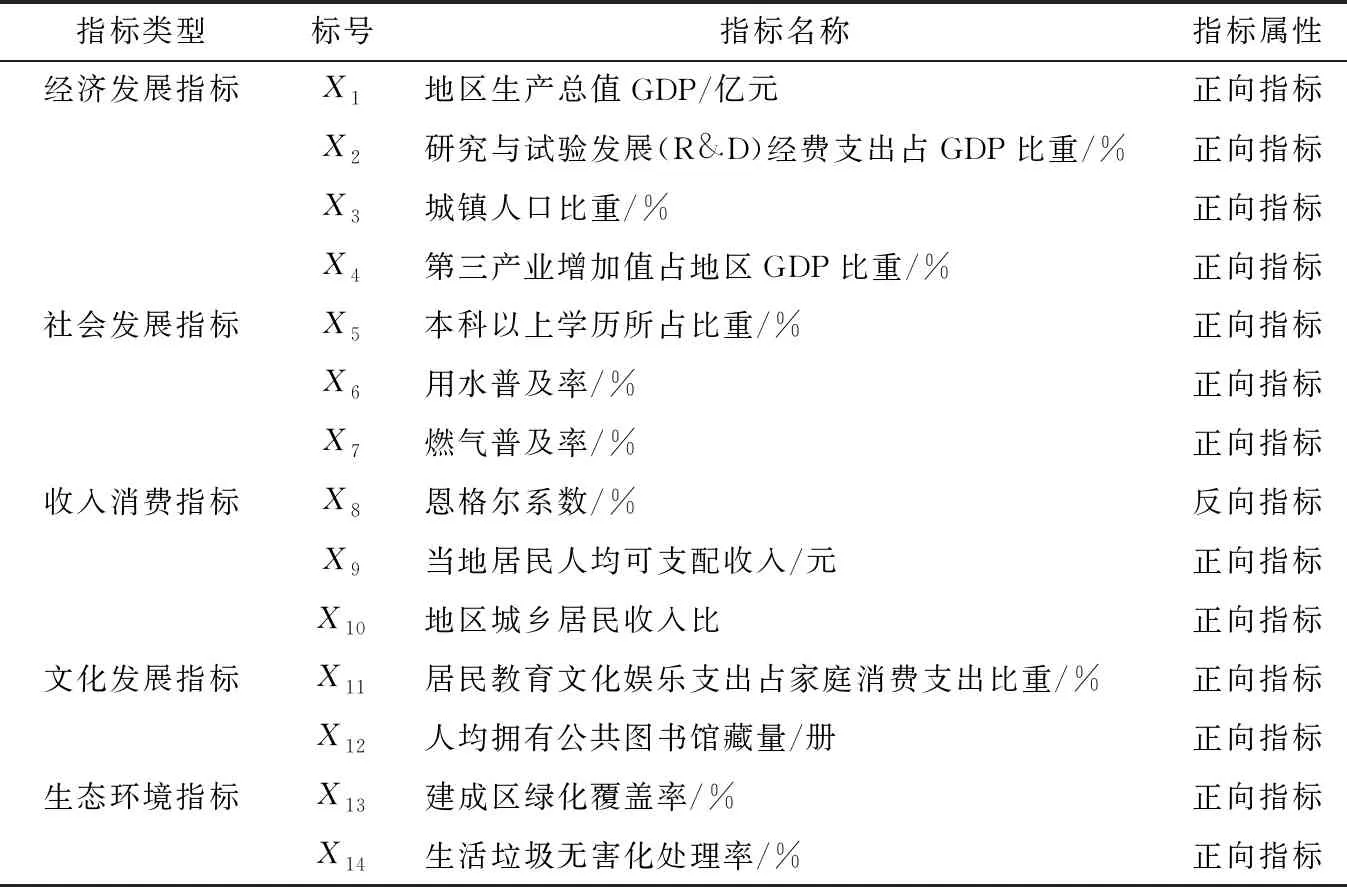
表1 全国共同富裕水平评价指标体系
研究与试验发展(R&D)经费支出占GDP比重:主要用于反映一个国家经济科技资金投入利用能力与技术水平,可直接反映一个国家经济科技发展实力。科学技术是发展生产力的关键路径,通过度量一个地区研究与试验发展(R&D)经费的投入情况,可有效地评判该地区科技发展的状况,并反映生产力水平优劣,从而评判当地人民的生活水平情况。
城镇人口比重:城镇人口即所从事的产业为非农业生产性的人群及其家庭。一般认为城镇人口占有率的高低反映出一个地区的工业化、城镇化及城市化水平。伴随着改革开放的脚步,中国的经济国情由原先的农业大国逐步向工业大国转型。城市化是人类发展的必然趋势,是国家现代化的必由之路,也是提升人民生活幸福感的必经之路。
第三产业增加值占地区GDP比重:即某一地区第三产业增长量占GDP总量的比重。第三产业主要指服务业和除农业、制造业以外的其他商业。第三产业增加值占GDP的比重情况,可有效评判一个地区的经济发展情况,若第三产业发展较好,则可间接地表明某一地区现代化程度高。由此,可作为评价经济发展的重要指标。
(2)社会发展指标(3个)
本科以上学历所占比重:反映某一地区国民总体接受高等教育的覆盖率。教育是国家发展的基础,国民素质的提升间接影响着国家经济和文化软实力的发展。随着中国的经济社会发展,居民的受教育程度有一定的提升,一个地区人民的受教育程度可作为评价该地区社会发展好坏的间接特征。
用水普及率:反映某一地区居民的用水情况基础设施建设的水平,可以反映出城市化水平和现代化进程。
燃气普及率:反映某一地区居民的燃气使用情况基础设施建设的水平,同样可以反映出城市化水平和现代化进程。
(3)收入消费指标(3个)
恩格尔系数:是指在中国整个社会公共消费品生产总支出之中,食品支出占整个家庭消费总支出的实际占比情况。它主要体现的是经济科学含义,广泛被用来作为反映中国居民生活消费水平和消费质量稳定提升的一个重要经济指标。
当地居民人均可支配收入:是指当地居民人均可支配用于最终生活消费品的支出和最终储蓄的收入总和,反映某一地区的居民总体收入水平。一般认为,富裕、经济高度发展的地区,居民总体收入水平高;反之,经济萧条的地区,居民总体收入偏低。
地区城乡居民收入比:主要反映某一行政区域内,城市居民人均收入与农村居民人均收入的实际差异程度。这一指标可以作为衡量减少贫富差距、实现共同富裕程度的评判指标。
(4)文化发展指标(2个)
居民教育文化娱乐支出占家庭消费支出比重:反映某一地区居民的文化娱乐程度,可以用来评价居民幸福程度的高低。居民的幸福程度与GDP发展同样重要,一方面,它可以调控经济社会运行态势;另一方面,它可以了解民众的生活满意度。作为最重要的非经济因素,文化发展水平可以作为有效评价人民小康生活情况的重要指标。
人均拥有公共图书馆藏量:反映某一地区居民纸质书籍的阅读量,这一指标可以用来评价社会提供优良公共文化服务的能力。
(5)生态环境指标(2个)
建成区绿化覆盖率:建成区绿化覆盖率是指城市建成区绿化覆盖面积占建成区的比率。其高低可以作为衡量城市环境质量及居民生活福利水平的重要指标。现阶段,中国经济社会不断发展,广大人民的幸福程度和满意程度大幅提升,总体幸福指数也得到大幅提升,但生态环境问题也开始日益显现,从注重“温饱”逐渐转变为注重“环保”,从“图生存”到“图生态”。改变环境质量已是广大人民群众的热切期盼,也可作为评判一个地区发展均衡性的评价指标。
生活垃圾无害化处理率:是指报告期生活垃圾无害化处理量与生活垃圾产生量的比率。在统计上,由于生活垃圾产生量不易取得,可用清运量代替。这一指标可用来衡量对城市垃圾进行减量化分选和资源化利用的效率。实现生活垃圾的无害化处理,有利于实现资源的合理循环,这也是响应国家节能减排的要求。
3.指标数据处理
(1)反向指标正向化处理。恩格尔系数是评价指标体系中唯一一个反向指标,需对其进行正向化处理,具体做法是用100减去原始恩格尔系数,得到除去食品支出以外的消费支出占家庭总支出的实际比重。
(2)数据标准化处理。数据的标准化处理可消除不同量纲差异的影响,采用Z-score标准化处理,具体过程在下文PCA评价方法中有详细介绍。
(二)研究框架
基于选取的《中国统计年鉴》中2013—2020年31个省份的14个指标数据,首先,本文以中国2013—2020年纵向的时间跨度展开研究,目的是衡量近年来随着党中央政策推进,中国整体的共同富裕发展趋势。这一过程,选取PCA方法进行主成分的选取和中国共同富裕水平的测度。其次,以2020年为代表,深入研究这一年里全国31个省份的共同富裕水平差异,目的是测定中国南北、东西地域之间经济发展的不均衡性。这一过程借助PCA打分与K均值聚类相结合,将全国31个省份依据PCA的打分情况,划分为四个共同富裕评价等级。随后,结合2013—2020年全国31个省份共同富裕等级分布情况进行深入分析。最后,本文基于CNN模型在分类问题上的高效性,以每个省份所属等级作为标签,各个省份的共同富裕评价指标值作为输入矩阵,训练CNN模型。训练好的模型无需经过PCA打分和K均值聚类分析,直接输入一个省份的共同富裕评价指标,即可得所研究省份的共同富裕画像情况。
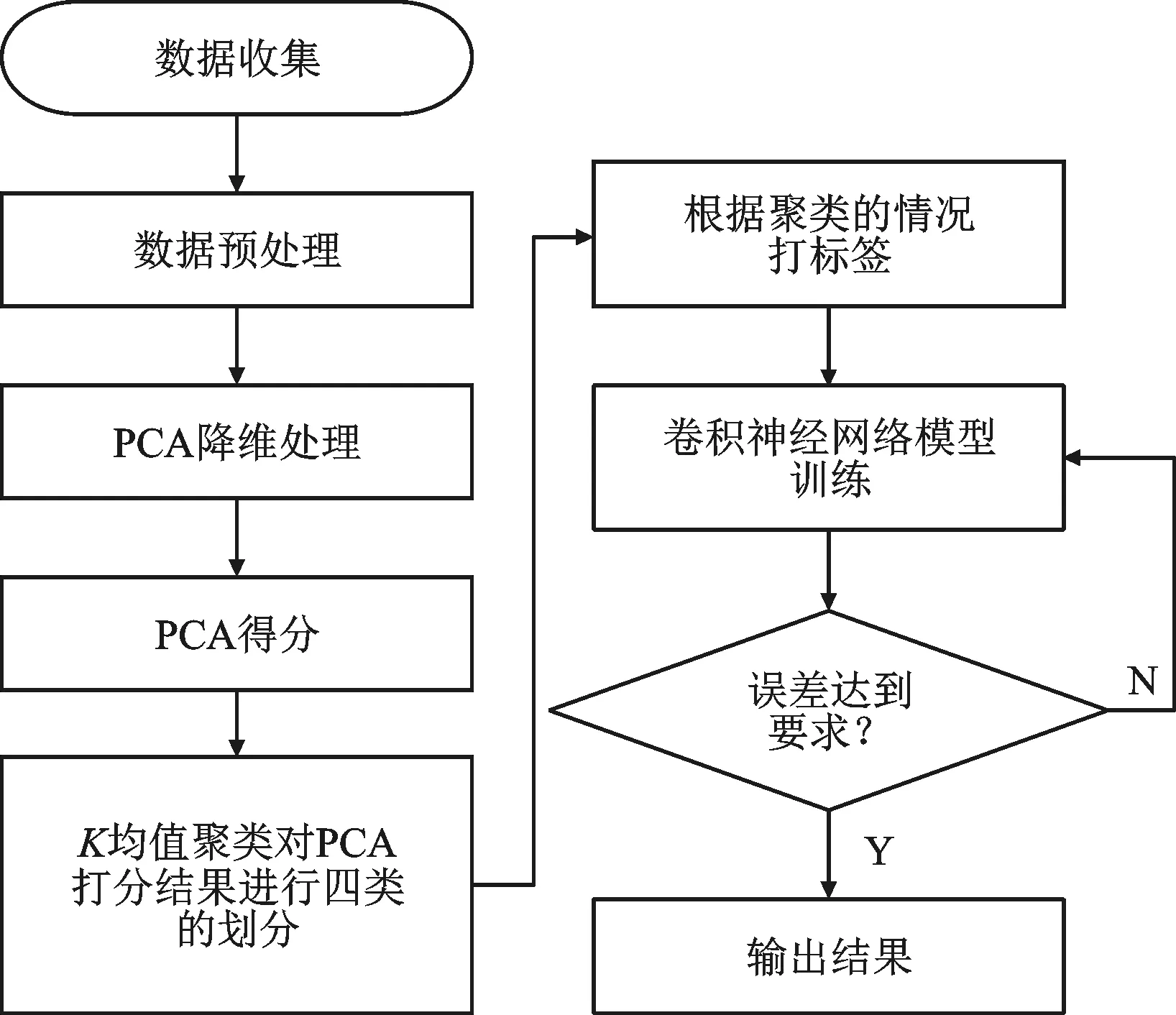
图1 PCA-CNN模型框架图
根据以上分析,构建PCA-CNN中国共同富裕水平评价模型的整体思路为:(1)构建共同富裕的评价指标体系,对数据进行预处理。(2)运用PCA进行指标精简和优化,并对输入的样本数据进行综合打分。(3)运用K均值聚类算法对PCA打分结果进行聚类划分,按得分的高低分布划分为A+、A、A-、B四个评定等级并对每个省份所属类打标签。(4)构建卷积神经网络(CNN)模型,以输入评价指标为基础进行训练,以每个省份所属类的标签作为预测目标。模型框架图见图1。
图2 主成分算法示意图
(三)研究方法概述
1.主成分分析(PCA)的评价方法
主成分分析法是一种常规的多变量降维分析方法[18]。该算法原理如图2所示。
主成分分析法具有使系统数据集更易投入使用、大大降低了该算法的系统计算成本、有效去除系统噪声的诸多优点。本文运用MATLAB R2018a软件进行主成分分析,处理过程如下:
首先,定义原始矩阵,见式(1);随后,进行数据Z-score标准化处理,见式(2)。
(1)
(2)
其次,计算相关系数矩阵。
(3)
式(3)中:rij表示原始变量di与dj的相关系数,取值范围为(1,j)。
然后按照特征值≥1.0进行主成分分析与提取,特征值为λi(i=1,2,…,P)。根据各个主成分的贡献率获得权重,计算综合得分。
主成分贡献率:
(4)
累计贡献率:
(5)
2.K均值聚类分析方法
分类等级的划分方法分为主观与客观两种,经过PCA打分后,如果人为对于打分结果进行等级的划分,属于主观方法。显然,主观分类存在人为的随意性,为了避免主观分类的不利影响,我们采用K均值聚类的客观分类方法。
K均值聚类算法步骤如下:
(1)初始中心取自于数据集中的K个对象,每个聚类中心用一个对象表示;
(2)根据样本中的数据对象与步骤(1)中聚类中心的欧几里得度量,按距离的就近原则将它们划分到距离它们最近的聚类中心所对应的类中;
(3)更新聚类中心,将每个类所有对象所对应的均值作为该类的聚类中心,计算目标函数的值;
(4)检验目标函数值与聚类中心的一致性,若一致,则输出聚类结果;若不一致,则返回步骤(2)。
本研究中设置K均值聚类数为4,目的是将中国各个省份的共同富裕程度划分为A+、A、A-、B四个等级,与张萌谡等学者的实验过程相似[21]。类内各数据点到聚类中心Cj=(Cj1,Cj2,Cj3,Cj4)的距离平方和计算如式(6)所示:
J(Cj)=∑xi∈Cj‖xi-Cj‖2
(6)
式中:‖·‖表示欧式距离;Cj为不同的类。
K个不同类的总距离平方和计算如式(7)所示:
(7)
隶属度矩阵Un×K的元素uij定义如下:
(8)
其含义为:如果数据点xi与聚类中心Cj距离最近,则xi属于Cj类。
3.卷积神经网络(CNN)模型
在K均值聚类的基础上,以每个省份所属等级作为标签,各个省份的共同富裕评价指标值作为输入矩阵,训练CNN模型。训练好的模型无需经过PCA打分和K均值聚类分析,直接输入一个省份的共同富裕评价指标即可得出所研究省份的共同富裕画像情况,即此省份共同富裕所属评价等级。
卷积神经网络(CNN)是一个多层的神经网络,较好地实现了对生物神经网络的模拟[22]。
本研究选取的是双曲正切函数Tanh(hyperbolic tangent function),如式(9)所示,Tanh函数与其他的激活函数相比,在处理一维卷积具有较高的准确率[31]。
(9)
其中,Tanh函数以0为中心进行输出,区间在-1~1之间。
此外,中间层采用Flatten层来连接卷积神经网络和全连接层。如式(10)所示,设定4个输出结点对应四个等级的共同富裕程度,损失函数(Softmax)将每个特征数据匹配到概率最大的特征类。
(10)
运用交叉熵损失函数(categorical crossentropy)作为模型训练的损失函数,如式(11)所示,它描述的是当前学习到的概率分布与实际概率分布的距离,也就是损失函数越小,两个概率分布越相似,此时损失函数接近于0。其中y为期望的输出,a为神经元实际输出,C为待分类的类总数。
(11)
本文采用Keras框架来搭建神经网络,经过了多次调参,最终使用了3层卷积层来提取特征值。其中,第一层卷积中滤波器的输出数量设置为16,卷积窗口的长度设为3。第二层卷积中滤波器的输出数量设置为64,卷积窗口的长度设为3。第三层卷积中滤波器的输出数量设置为64,卷积窗口的长度设置为3。每层卷积层后添加了一层最大池化层,池化层深度设为1,目的是保留主要特征,减少计算量。全连接层的参数设置为4,目的是为了预测划分好的四个类的准确率。最终输出一个预测的标签值。网络结构见图3。
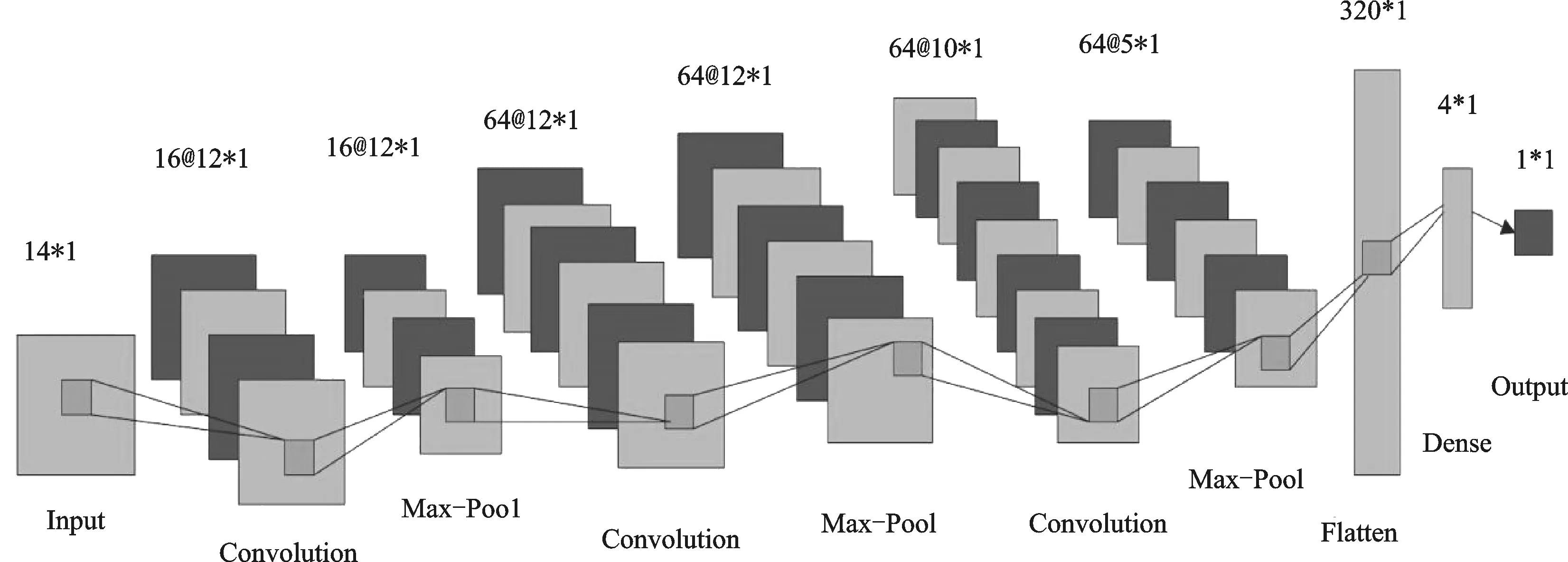
图3 一维卷积神经网络框架图
(一)中国共同富裕评价及结果分析
运用MATLAB R2018a软件对输入评价指标的原始矩阵运用Z-score法进行标准化处理,随后通过PCA降维处理,可以分析主成分对于原始指标信息的综合程度。以2020年为例,运用PCA方法进行指标处理(见表2)。
由表2可知,使用PCA的分析方法,提取4个特征值大于1的主成分,这4个主成分累计方差贡献率达到75.793%,说明包含了原14个评价指标中75.793%的信息,因此判断这四个主成分可以很好地代替其他指标来评价全国共同富裕情况。
在提取4个主成分后,输出主成分得分系数矩阵(见表3)。
结合表2、表3分析得出,在提取的4个主成分中,每个主成分分别与选取的14个指标中的几个呈正相关的关联,可被用来综合反映全国各省份间共同富裕的测度水平。
(1)PC1主要与X1、X2、X3、X4、X5、X6、X7、X9、X12、X13正相关。X1代表地区生产总值GDP;X2反映国家科技投入能力与水平;X3表示城镇人口比重;X4代表第三产业增加值占地区GDP比重;X5反映某一地区国民总体接受高等教育的覆盖率;X6、X7均反映城市化水平和现代化进程;X9代表当地居民人均可支配收入,可反映一个地区居民的总体收入情况,也可作为度量共同富裕中“富裕”水平的依据;X12是指人均拥有公共图书馆藏量,反映了文化产业的发展水平;X13代表建成区绿化覆盖率,是衡量城市环境质量及居民生活福利水平的重要指标。综上,第一主成分覆盖了全国共同富裕水平的经济发展、社会发展、收入消费、文化发展和生态环境五个方面的情况。
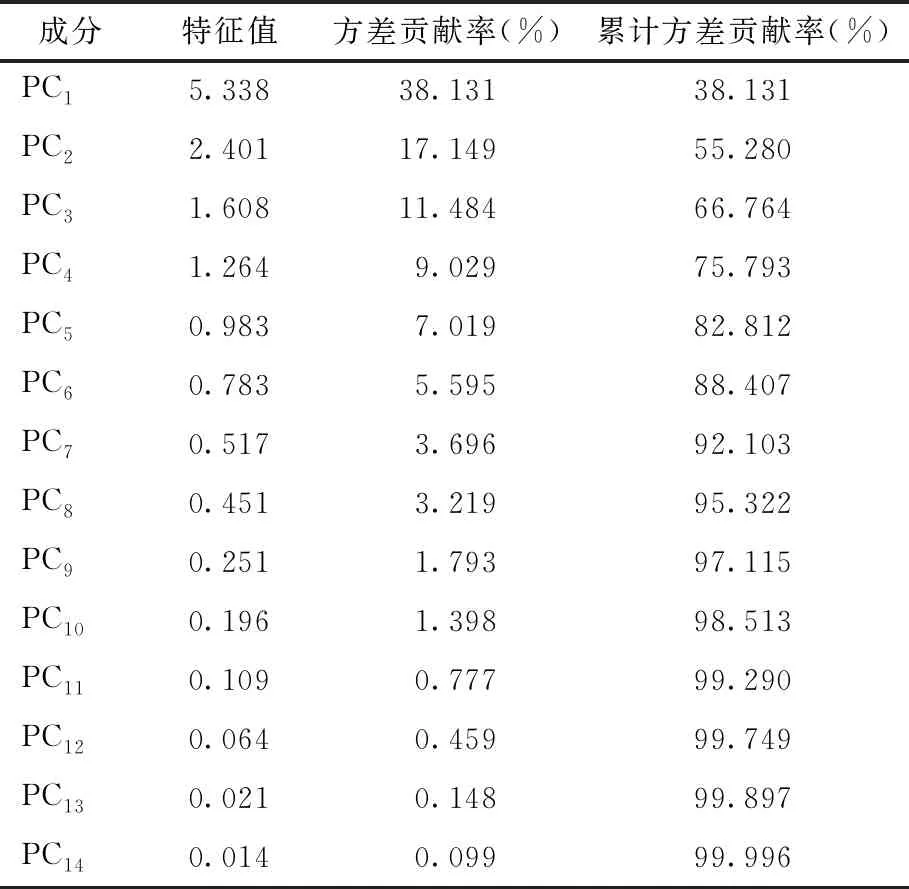
表2 主成分分析表
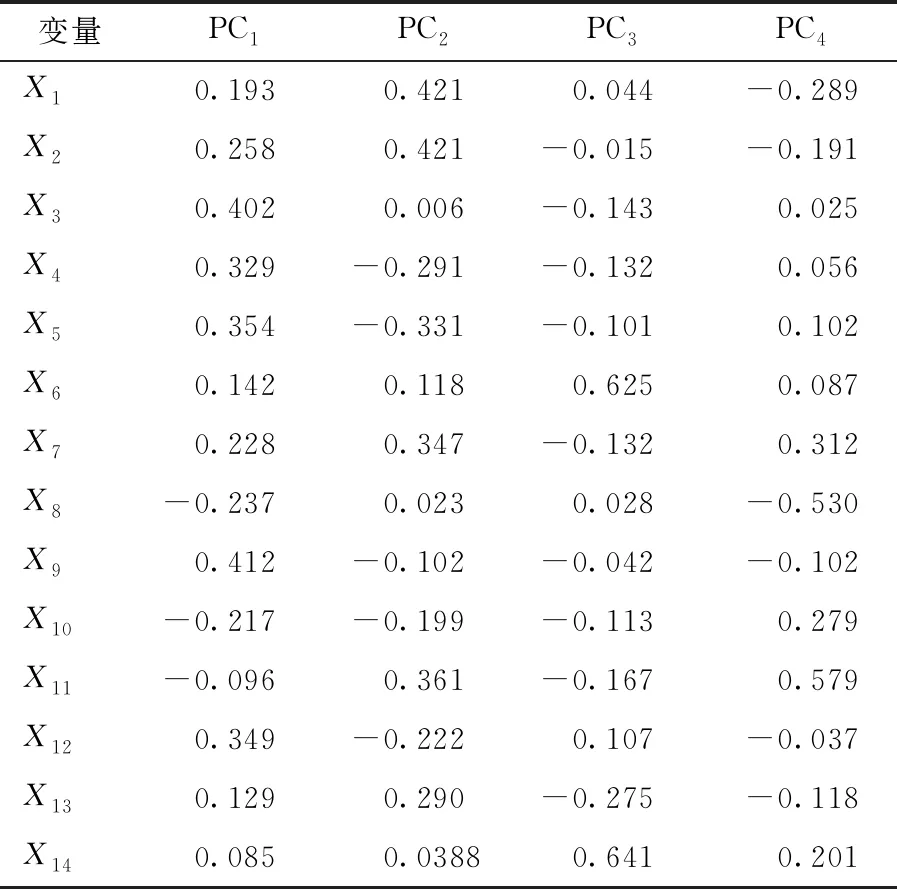
表3 主成分得分系数矩阵中的元素
(2)PC2主要与X1、X2、X6、X7、X11、X13正相关。其中,X1代表地区生产总值GDP;X2反映国家科技投入能力与水平;X6、X7反映城市化水平;X11代表居民教育文化娱乐支出占家庭消费支出比重,可反映居民的文化娱乐程度;X13代表建成区绿化覆盖率,体现了生态环境的建设情况。第二主成分可综合反映全国共同富裕的经济发展、社会发展、文化发展和生态环境四个方面的情况。
(3)PC3主要与X6、X12、X14正相关。其中,X6表示用水普及率,反映了城市化水平。X12反映了文化产业的发展水平。X14代表生活垃圾无害化处理率,反映了垃圾分类的进程以及资源化利用的效率。综上,第三主成分可综合反映全国共同富裕水平的社会发展、文化发展、生态环境三个方面的情况。
(4)PC4主要与X5、X7、X10、X11、X14正相关。第四主成分可综合反映全国共同富裕水平的社会发展、收入消费、文化发展和生态环境四个方面的情况。
此外,对2013—2019年的评价指标进行降维处理,结果同2020年一致。随后对2013—2020年各省份的共同富裕情况进行PCA打分,打分结果如表4(a)和4(b)所示。
由表4(a)清楚地看出2013—2020年全国各个省份的打分情况,同时计算出全国31个省份八年里的平均得分、最高得分和最低得分情况,如表4(b)所示。其中,正值代表高于全国整体的平均得分水平,负值代表低于全国整体的平均得分水平。由结果可以得出:
(1)东部地区得分普遍高于中、西部地区。其中,以北京、上海为代表的一线城市得分一直处于领先水平。浙江、江苏、山东、广东四省的共同富裕水平在2013—2020年发展迅速,结合其地理位置分析,位于东部沿海地区,贸易交通便利为其经济发展创造了有利的条件。同时,西部地区包括贵州、云南、西藏、甘肃、青海等地,其共同富裕平均得分还是与全国整体的平均得分水平有一定的差距,东、西部发展不均衡。
(2)结合南北区域发展来看,中国南部地区的得分情况要比北部地区得分略胜一筹。结合开放政策与历史环境分析,1978年以来,改革开放先从南方兴起,随后逐步输送至全国各地。所以,改革开放以来,开放发展的理念已经深深根植于南方地区广大民众的心中,而北方地区较之落后,还处在学习借鉴阶段。从对外开放条件看,不管是沿海开放带,还是长江沿线开放带,经济发展条件都比较完备。近年来,因为南方开放环境优越,国际贸易活跃,经济持续高水平发展。相比之下,北方地区经济发展显得较为逊色。
(3)2013—2020年各个省份的得分差距在逐渐缩小。以北京和浙江为例来看,2013年北京的得分为3.519,2013年浙江的得分为1.111,二者得分相差2点多。而2020年浙江的得分升至1.359,北京的得分为1.714,二者得分相差缩小至0.355。可见中国近年来共同富裕的推进有一定的成效,全国整体的经济水平处于发展状态,省际间的发展差异在缩小。
如图4所示,为了更加直观地显示中国共同富裕2013—2020年的快速发展进程,将31个省份2013—2020年共同富裕得分情况绘制在同一张图上。由图4可以看出,2019年、2020年全国31个省份的共同富裕情况与前六年相比,各个省份的富裕水平得分差异明显缩小。可见,随着经济的高质量发展与居民共享发展成果的互促互动,中国的共同富裕进程迈出了很大一步,各省份间的贫富差异得到了进一步的改善。
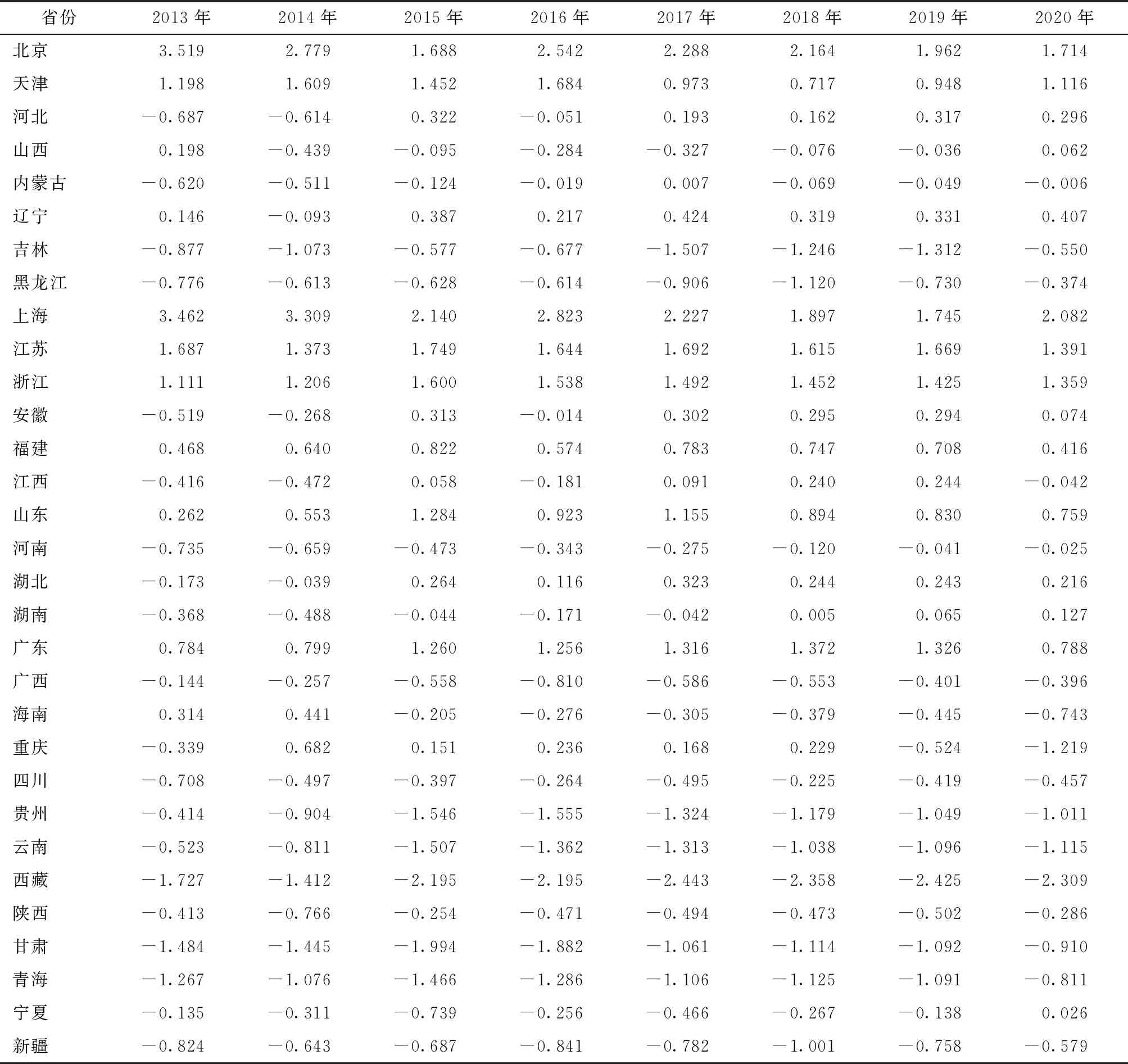
表4(a) 主成分得分情况表
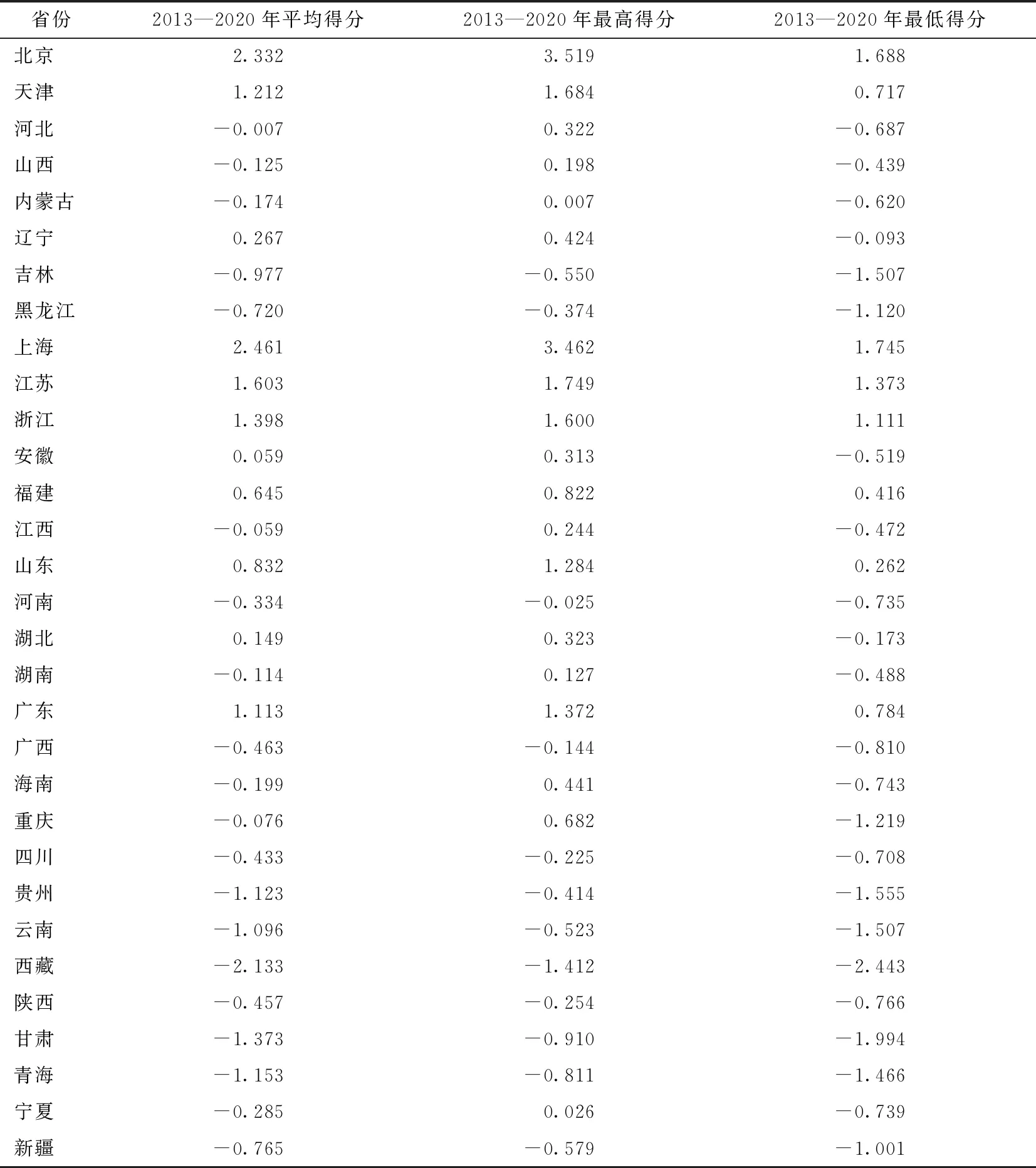
表4(b) 得分评价情况表
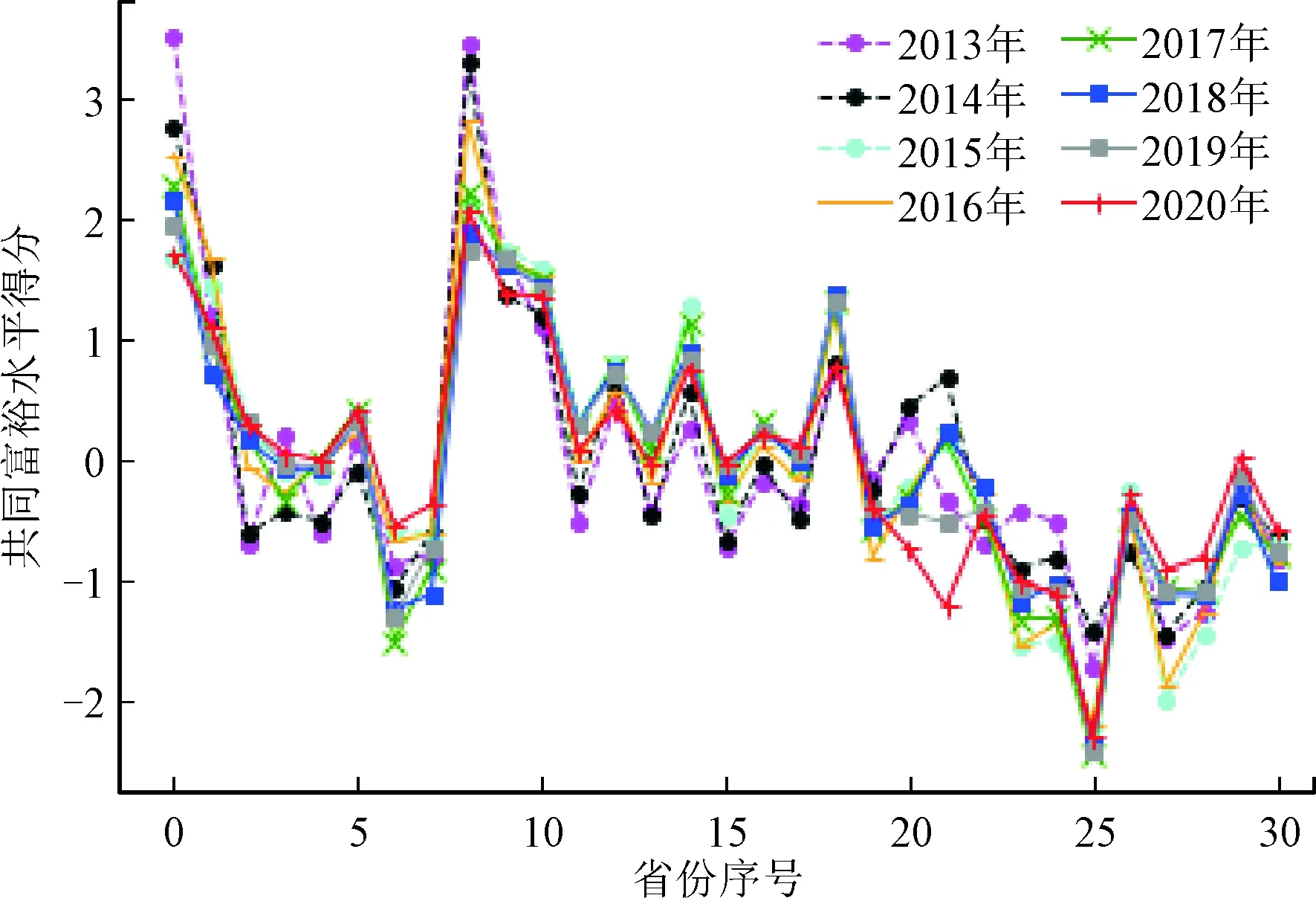
图4 不同年份中国省际间共同富裕水平的动态变化图
纵观2013—2014年的全国各省份共同富裕水平的曲线变化,整体波动较大,其中东部地区如北京、上海等地与以西藏为代表的西部偏远地区相比,得分差异悬殊。2015年,曲线逐渐趋于平缓。结合2016—2020年的曲线形势分析,五年里中国各省份的共同富裕水平呈现出了小幅波动的景象,部分省份得分存在差异,2020年曲线的最高点与最低点的距离最短,可以看出2020年中国的共同富裕程度最好。2013—2020年,中国共同富裕水平正在稳定推进。
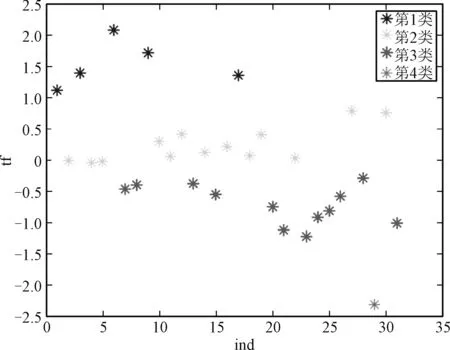
图5 2020年中国共同富裕水平聚类结果图
(二)全国共同富裕水平等级画像和结果分析
本文以MATLAB R2018a软件为实验环境,建立PCA模型对输入矩阵进行排序与得分。首先以2020年为例,运用K均值聚类方法对全国31个省份依据PCA得分情况划分为4类,代表着A+、A、A-、B四个评价等级(见图5)。
图5中横坐标ind代表31个省份各自的序号,纵坐标tf表示PCA对各个省份的得分情况。
对31个省份的聚类结果进行归纳与标签的标记,目的是代入深度学习模型进行预测(见表5)。tf值为PCA模型计算得出的31个省份各自的综合得分,Idx值为所属类的标签。其中,负得分并不代表指标水平为负,而是表示与平均水平的差距;正值代表高于平均水平,负值代表低于平均水平。
其K均值聚类得到的聚类质心和打标签及等级划分情况见表6。
标签打为1表示评价等级为A+,聚类质心为1.532;标签打为2表示评价等级为A,聚类质心为0.238;标签打为3表示评价等级为A-,聚类质心为-0.704;标签打为4表示评价等级为B,聚类质心为-2.309。用这四个评价等级来衡量2020年全国31个省份共同富裕水平。
将2020年全国31个省份的共同富裕评价情况绘制在同一表上。从表7可以直观地看出2020年中国31个省份四个评定等级的分布情况:(1)2020年评价等级为第一类的省份有北京、天津、上海、江苏、浙江。(2)评价等级为第二类的省份较多,包括河北、山西、内蒙古、辽宁、安徽、福建、江西、山东、河南、湖北、湖南、广东、宁夏。(3)评价等级为第三类的省份也较为集中,包括吉林、黑龙江、广西、海南、重庆、四川、贵州、云南、陕西、甘肃、青海、新疆。(4)评价等级为第四类的省份只有西藏一个省份。
表5还可以看出,评价等级为一类的省份主要为东部沿海地区。相反,评价等级为第四类的省份为西部边缘地区,经济发展相对落后,人民生活水平相对较低。结合2020年全国各省份共同富裕得分情况来分析,评价等级为第四类的省份平均得分只有-2.309,与全国平均得分相比存在一定的差距,而评价等级为第一类的省份平均得分可达1.532,与第四类评价等级省份的平均分相差3左右,第一、第四类等级的省份得分差异较明显。但宏观来看,全国大部分省份位于第二、第三类评价等级。2020年,全国31个省份共同富裕情况呈现出“橄榄型”分布,表明社会阶层结构中极富极穷的“两极”很小而中间阶层相当庞大。可见2020年全国共同富裕成效显著,距离“大同社会”又近了一步。
从全国的南北区域等级分布来看,南部地区经济发展略好一些,可能是由于历史因素所造成的,改革开放先从中国南方开始,南方开放环境优越,国际贸易发展活跃。如何有效地带动北方经济的发展是一个亟待解答的问题。结合自然条件来看,新疆、内蒙古等北部边陲地区,商品经济发展受限,但自然资源丰富,可以利用其优势发展畜牧业和旅游业来带动当地经济的发展。
运用同样的方法分别对2013—2020年的共同富裕水平动态演变过程进行深入分析(见表7)。
表7清楚地呈现了全国31个省份2013—2020年的等级评定演变结果。从2013—2020年整体来看,北京和上海一直处于第一类评价等级,其富裕水平就全国来看一直走在前列。而以天津、江苏、浙江、广东四个省份为例进行深入研究,可以发现,天津、江苏、浙江、广东在2013年时,其评价等级分别为:A、A、A、A;2015年,其评价等级变为:A、A+、A+、A;2018年,其评价等级分别为:A、A+、A+、A+;到2020年,其评价等级变为:A、A+、A+、A。可以看出,这些省份主要为东部沿海地区,改革开放以来,中国的发展很迅速,靠近港口的地区,经济优先发展起来。共同富裕的最终要求是实现富裕的均等化,所以在2020年,部分省份由第一等级变为第二等级,这并不是富裕水平的倒退,而是地区差异缩小导致的。再以中国的中部地区展开研究讨论,2015—2020年,有许多第三类的省份逐步转变为第二类。诸如河南、河北、安徽、湖北、湖南、江西等省份,在此期间可能受东部地区城市的经济带动,中部城市的发展也迈出了一大步。
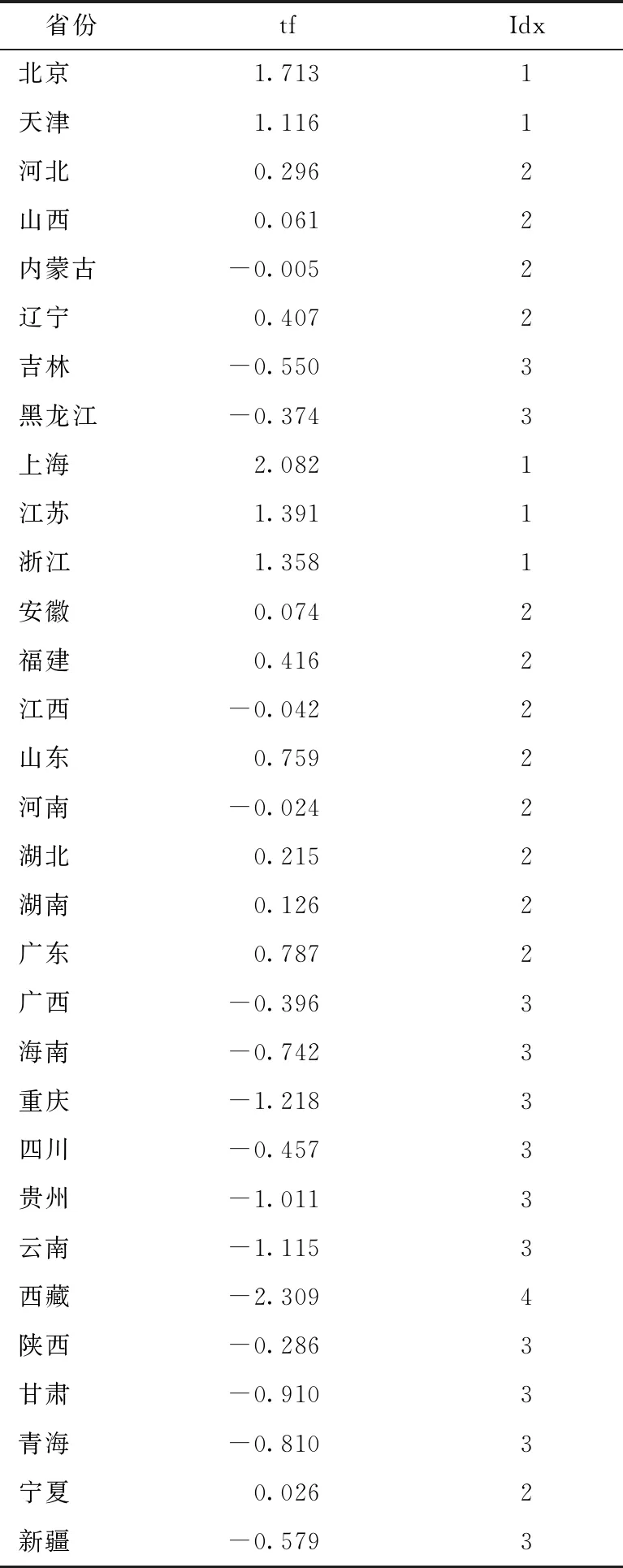
表5 2020年全国共同富裕水平得分评级情况

表6 K均值聚类情况
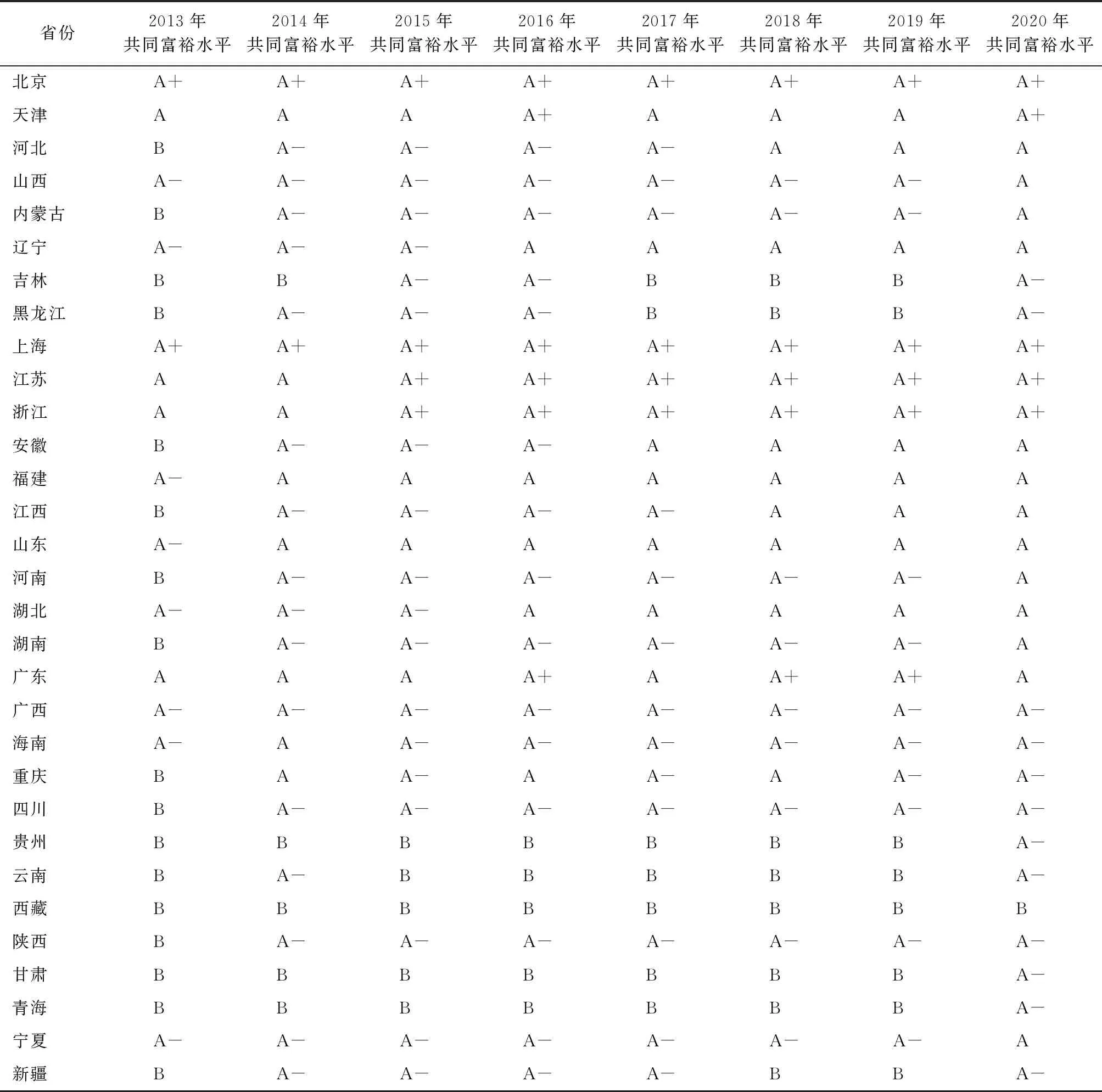
表7 2013—2020年中国共同富裕水平演变进程
2013年,全国31个省份共同富裕情况呈现出“金字塔型”分布,是一种贫富差距较大的社会结构。可以看出2013年,中国绝大多数省份都处于第四类评价等级,处于第一、第二、第三类评价等级的省份较少,表明2013年共同富裕正处于起步阶段,中国经济整体不是很景气,全国的地域发展差异较为明显,除极个别省份的人民过上了小康生活,大多数人民依然生活水平不高,实体经济发展仍需完善。
2015年,全国31个省份共同富裕水平有一定的提升。绝大多数中西部地区,富裕水平已由第四等级提升至第三等级。同时,东部沿海地区,少数省份共同富裕水平已发展为第一、第二类评价等级。可以得出结论:到2015年,中国共同富裕处在缓慢发展阶段,但东、西部区域之间发展不均衡,整体共同富裕水平还未显著提升,政府应在稳抓经济的同时,促进先富带动后富,推进共同富裕的发展进程。
2018年,相比2015年,经历了三年的经济蓬勃发展,中国31个省份的富裕水平已大幅度提升。在2015年的基础上,第一类评价等级的省份已有5个,第二类评价等级的省份有9个。第一、第二类评价等级的省份加起来占到全国31个省份总数的一半左右,人民生活显著提升。但是,“共同”的要求还未得到实现,第一、第二类评价等级的省份主要分布于东部,中西部地区发展仍需推进。分析得出:2015—2018年,中国共同富裕已处在加速阶段,但共同富裕不仅停留在“富裕”的字眼上,更应该关注“共同”的要求上,坚持从“全方位、多角度、多层次”视角出发,推进中国省际间的均衡发展。
2020年,全国31个省份共同富裕情况呈现出“橄榄型”分布,共同富裕水平显著提升。第一、第四类评价等级的省份只有5个,而且其中第四类评价等级的省份只有西藏1个,第二、第三类评价等级的省份占据绝大部分。从全国共同富裕的进程来看,全国共同富裕正在稳定地推进。
此外,为了深入研究对全国各个省份共同富裕水平影响较大的评价指标,以2020年为例,进行各评价指标每个等级下的平均水平计算(见表8)。
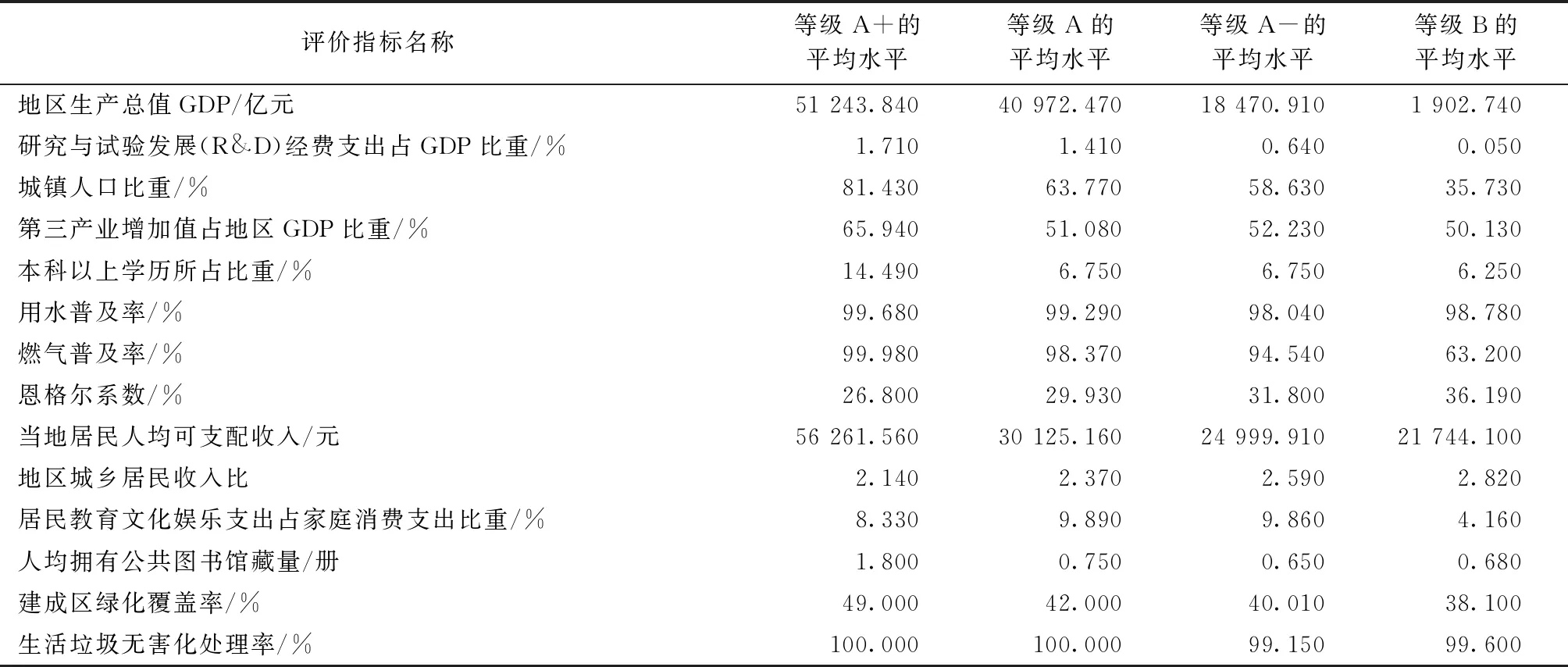
表8 2020年全国共同富裕各评价指标每个等级下的平均水平情况
由表8可以看出,等级A+与等级A之间差异较大的指标有:(1)地区生产总值GDP;(2)城镇人口比重;(3)第三产业增加值占地区GDP比重;(4)本科以上学历所占比重;(5)当地居民人均可支配收入;(6)人均拥有公共图书馆藏量。由此可知,影响第一、第二类评价等级较为重要的因素在经济发展、社会发展、收入消费和文化发展四个方面中均有体现。等级A与等级A-之间差异较大的指标有:(1)地区生产总值GDP;(2)研究与试验发展(R&D)经费支出占GDP比重。说明影响第二、第三类评价等级中较为重要的因素主要体现在经济发展这一层面。等级A-与等级B之间差异较大的指标有:(1)研究与试验发展(R&D)经费支出占GDP比重;(2)城镇人口比重;(3)燃气普及率;(4)居民教育文化娱乐支出占家庭消费支出比重。说明影响第三、第四类评价等级中较为重要的因素主要体现在经济发展、社会发展和文化发展三个方面。
综上,通过比较测算各个评价等级间指标的差异性,可发现共同富裕的发展进程中,覆盖居民的经济发展、社会发展、收入消费和文化发展四个方面均存在发展不平衡的问题。结合上述各个等级间影响评定结果较大的评价因素,可以为政府部门提出一些切实有效的建议,从而更好推进全国共同富裕的发展进程。
(三)运用深度学习预测全国共同富裕等级分类
由于PCA得分和K均值聚类结果只能按部就班地对现有的指标数据进行评价和画像,其过程较为繁琐,不能直接对未知的输入指标进行预测划分等级。可运用卷积神经网络(CNN)模型对大数据预测分类准确的特点,以2020年为例,选用CNN模型进行预测。
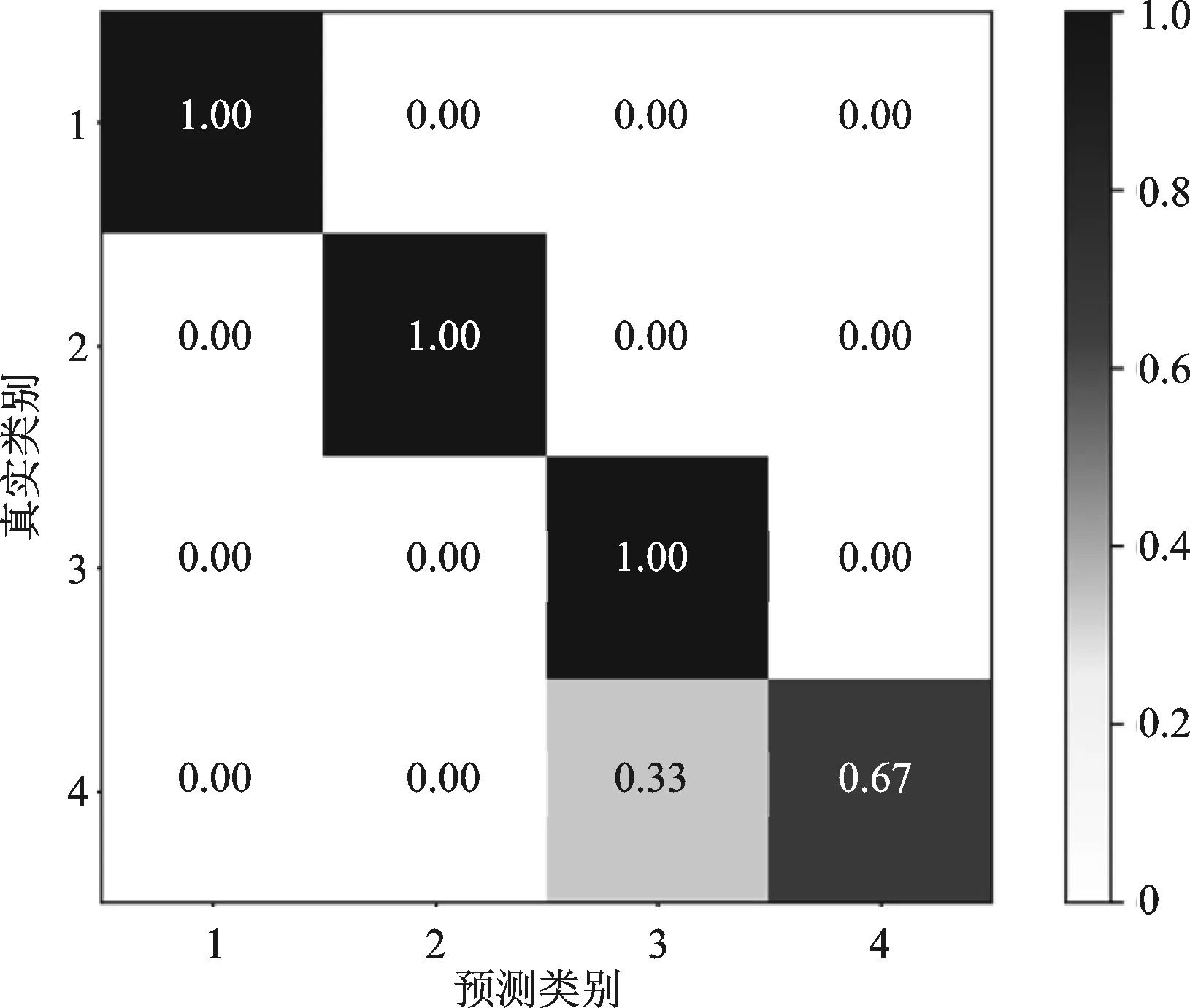
图6 CNN预测2020年全国共同富裕水平分类热度图
1.样本训练
在主成分分析(PCA)得分与K均值聚类的基础上,将31个省份依据评价得分划分的标签,作为卷积神经网络(CNN)要预测的目标值。实验环境为Python 3.7,首先,对输入数据进行数据归一化处理,采用离差标准化,对原始数据进行线性变换,使结果值映射到[0,1]之间。其次,对原始输入数据进行训练集与测试集的划分,划分标准为7∶3;样本数据的14个评价指标作为输入的特征信息,最后一列标签值为预测对象。参数设置:实验的迭代次数设置为1 000次,神经网络的参数设置同上文,激活函数采用Tanh函数。学习率经多次实验,设置为0.001效果最佳。Dense设置为4,目的是为了预测划分好四个等级下各自的准确率。
模型训练的结果见图6。由图6可以清楚看出,由于第四类评价等级下面只有西藏1个省份,模型预测受数据限制,准确率只有67%。除第四等级以外,其余3个评价等级下的预测程度较好,其预测准确率均可达到100%。整体来看,模型可有效对全国31个省份共同富裕情况进行预测与智能分类。
2.模型评价
本研究共训练了1 000次,每次迭代结果通过测试准确率test accuracy、训练准确率train accuracy和测试损失函数test loss、训练损失函数train loss四个指标来评价预测的优劣,如图7所示。实验的平均训练准确率可达到99.8%,实验的平均测试准确率为91.6%。数据集中,不同标签间的层次性优劣对于分类问题的精确性有着直接的作用。模型每次训练的损失函数loss值在0~0.2之间,实验具有较高的准确性。模型可运用于全国共同富裕水平的智能画像预测。
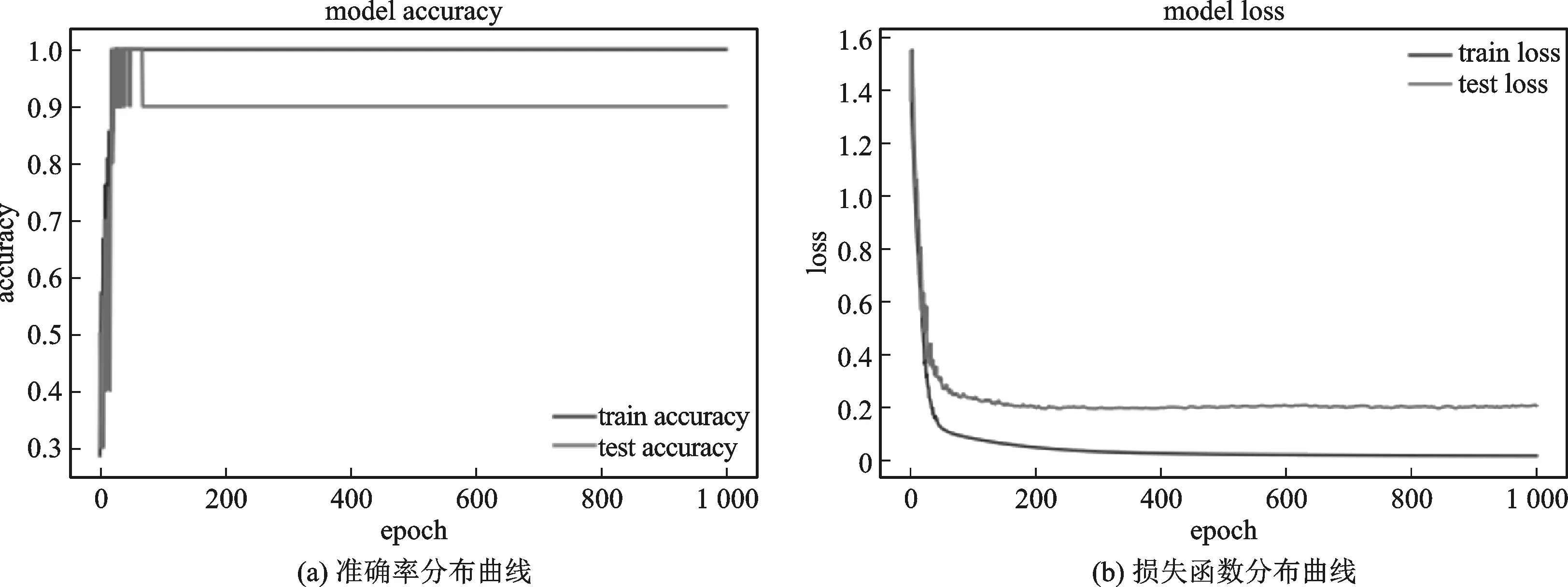
图7 CNN模型训练与测试评价曲线
(四)对比模型研究结果分析
实验在PCA得分与K均值聚类的基础上,运用多层感知器(MLP)模型以及支持向量机(SVM)模型、KNN模型,BP神经网络模型等传统模型作为对比实验,与本研究的CNN模型相比较,不同模型的参数设置如表9所示。
SVM模型选取了RBF核函数,KNN模型基于KFlod函数将数据集划分成10份,其中1份作为交叉验证数据集来计算模型准确性,剩余的9份作为训练数据集。MLP模型的参数设置同上文,学习率同CNN模型一样设置为0.001,迭代次数也设置为1 000次,每次训练输入8个样本数据。BP神经网络模型隐藏层节点数设置为64、学习率设为0.05时效果最佳。
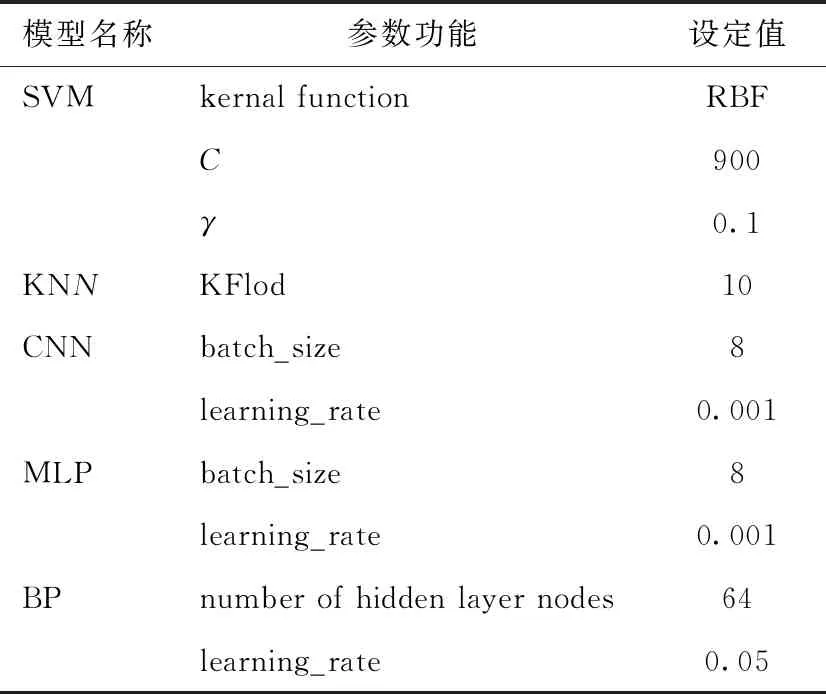
表9 CNN、MLP、BP、SVM和KNN模型参数表
表10对比了上文所选模型的训练及预测准确率情况,可以清楚地看出各种模型的预测效果。
由实验结果可以看出,所选的四种对比模型中:SVM模型平均训练准确率达到95.2%,平均测试准确率达到89.5%,与本研究的CNN模型具有相近的准确率,模型预测效果较好;KNN模型的平均训练准确率有87.5%,平均测试准确率达到85.7%;MLP模型平均训练准确率达82.1%,平均测试准确率只有71.4%,实验效果相对较差;BP模型预测的平均训练准确率达89.5%,平均测试准确率达86.5%。综上可见,PCA模型评分方法具有较好的效果,PCA与CNN结合可有效应用于中国共同富裕水平评价问题。本研究引入深度学习的方法来对中国共同富裕水平进行综合评价,可有效克服传统评价方法带来的繁琐、低效、易出错的劣势。政府部门可借鉴这种测度方法,将共同富裕水平走势高效地画像出来,由此发现社会发展存在的问题,以便更好地进行政策调整与制度变革。

表10 不同模型预测结果比对情况
(一)结论
共同富裕是现代化建设的重要特征,目标明确,全民期待。因此,对其进行准确解读、科学监测、客观评价就显得尤为重要。本文提出了一种基于主成分分析与深度学习相结合的方法,用于评价研究中国社会共同富裕水平。运用主成分分析(PCA)的方法对数据指标进行处理与综合打分,同时结合无监督学习K均值聚类的方法,将PCA打分结果划分为四类评价等级,最后运用卷积神经网络(CNN)模型进行训练。通过对现有共同富裕评价体系的研究学习及对相关文件、报道的深刻解读,构建了覆盖经济发展、社会发展、收入消费水平、文化发展、生态环境五个层面的14个评价指标,并进行深入研究。本文所引用实验数据均来源于国家统计局2013—2020年的《中国统计年鉴》。
研究结果表明:(1)相比于2013—2018年各省份的共同富裕评分情况,2019—2020年中国社会共同富裕程度显著提升,各省份贫富差异显著缩小,为激发民众发展潜力创造了更加普惠公平的条件;(2)以北京、上海为代表的东部地区经济发展较为迅速,人民生活水平普遍优于西部地区;(3)主成分分析法(PCA)与卷积神经网络(CNN)模型相结合的方法对于预测全国共同富裕水平具有较好的效果,该模型的平均预测准确率达到91.6%,可有效运用在全国共同富裕水平的智能画像预测上。
(二)政策建议
本研究有利于进一步缩小东、西部地区收入差距,推动全国共同富裕发展进程;同时,也有助于相关部门根据文中所提到的影响共同富裕水平的几个因素,结合以西藏为代表的西部偏远地区的经济发展现状,及时调整发展策略。此外,本研究还指出:部分地区的政府部门应加快提升地区生产总值GDP,增加该地区研究与试验发展(R&D)经费支出占GDP的比重,提高居民人均可支配收入,有效改善居民生活水平。同时,应注重文化产业的建设,着力解决好人民群众急难愁盼问题。具体政策建议如下:
(1)推动科研教育事业发展。适当增加R&D经费支出的总量,同时适当提高基础研究和应用研究在R&D经费支出中所占的比重。国家对于中、西部地区的科研教育事业投入水平相比一线城市明显不够,应适当增加项目经费与人才引进政策。财政科技投入不仅能够在很大程度上弥补企业研发资金的不足,而且能够显著地降低企业技术研发和创新活动进行的成本和风险,更重要的是:财政科技投入能够发挥显著的导向作用,形成以政府为主导、企业和银行为主体的科技投入体系,发挥财政的激励作用,推动科技创新。
(2)继续大力发展生产力。科学技术作为第一生产力,它不仅可以对劳动生产率产生直接的积极影响,还可以提高劳动过程中的外部效应和各种生产要素的收益。此外,推动“城投部门”市场化转型,剥离政府融资职能,通过对地方国有企业变相融资行为的审查问责,监督政府建立完善债务风险评估预警和应急处置机制,进而推动政府债务信息公开透明。这一举动,将极大增强民众的信任感,提升人民的满意度。
(3)普惠共享公共服务。首先,政府部门应加大地方财政扶持力度,努力缩小城乡居民人均收入差距,以促进城乡之间的物质共享。其次,应加快基础设施建设,特别是关注西藏地区的建设,完善社会基础设施建设,提升人民群众的幸福感。最后,兴建公共图书馆,增加藏书量,努力提升居民文化教育水平、拓宽文娱形式。扩大高等教育招生人数,从而为东、西部地区融合发展输送更多的人才,以促进不同省际间的均衡发展,推动共同富裕发展进程。
(三)讨论
本研究基于中国2013—2020年31个省份的相关数据,通过手动整理和导出的方法进行获取,从纵向分析了2013—2020年中国东、西部地区共同富裕发展历程及南、北区域差异的历史影响因素。以2020年为例,从横向分析了全国31个省份间经济发展情况、共同富裕水平的差距。考虑到数据的准确性、可获得性,共同富裕评价指标体系尚不够完善,仅纳入部分参考指标,因此本文的指标体系有待进一步优化。随着新时代的发展,共同富裕思想的精神内涵会不断丰富,因此对于共同富裕水平的评价也是一个不断探索的过程,评价方法以及评价指标也必将随着研究的深入而更趋全面、准确、科学。
猜你喜欢共同富裕省份聚类论中国式共同富裕的基本特征社会科学战线(2022年9期)2022-10-25Palabras claves de China今日中国·西班牙文版(2021年12期)2022-01-01在高质量发展中促进共同富裕当代陕西(2021年16期)2021-11-02金湖:美丽生金,让共同富裕看得见摸得着华人时刊(2021年21期)2021-03-09谁说小龙虾不赚钱?跨越四省份,暴走万里路,只为寻找最会养虾的您当代水产(2019年11期)2019-12-23基于K-means聚类的车-地无线通信场强研究铁道通信信号(2019年6期)2019-10-08基于高斯混合聚类的阵列干涉SAR三维成像雷达学报(2017年6期)2017-03-26一种层次初始的聚类个数自适应的聚类方法研究电子设计工程(2015年6期)2015-02-27因地制宜地稳妥推进留地安置——基于对10余省份留地安置的调研中国土地科学(2014年4期)2014-03-01自适应确定K-means算法的聚类数:以遥感图像聚类为例华东师范大学学报(自然科学版)(2014年6期)2014-02-27