赵 姝 李筱蔚 金 鑫
北京电子科技学院,北京市 100070
随着社交应用软件的普及,人们希望获得兼具美观和独特性的图片作为自己的头像,增加自己交友的魅力。
从最开始只能从软件提供的头像中做选择,到如今各式各样的图片都能成为头像,不难看出,人们的审美在不断提高。
但如果使用现实生活中的真人图片作为头像,可能会给头像本人在现实生活中带来负面影响,甚至产生道德和法律上的纠纷。
同时,品牌代言在真人明星形象的使用上存在时效性,若在解约后继续使用,必然引发肖像权纠纷等问题。
在人工智能、神经网络快速兴起和发展的当下,大量研究人员对生成对抗网络(GAN)进行了研究。
GAN 模型最初由Ian J. Goodfellow 及其团队于2014 年在《Generative Adversarial Nets》[1]中提出,之后广泛应用于图像生成领域,弥补每类样本图片较少的问题。
目前,国内外用于虚拟人像生成的软件还很少,大多数是挂在服务器上做的网页,比如最出名的是“This person does not exist”网页[14],每次刷新网页就能生成一张新的虚拟人像图片,规格大小为1024 * 1024,因为用于训练的数据集中欧美人占了大多数,网页生成的图片大多以欧美人像为主。
后来也有一些研究者开始用亚洲人脸、动漫头像等数据集来训练模型,甚至使用车、猫、房子等数据。
本文收集并制作了包含5861 张人脸图像的日式大头贴数据集,学习、对比了多种GAN 技术,最后确定利用StyleGAN2 网络来训练数据集,生成神经网络模型;
使用Flask 框架进行服务端的部署,利用Android Studio 进行客户端开发;
实现了在安卓手机APP 上的人机交互,能够生成并保存虚拟人像图片,避免了实际生活中肖像权纠纷等问题。
1.1 生成对抗网络
生成对抗网络的框架由独立的生成器G 和鉴别器D 组成的[15]。
生成器G 的作用是生成不存在的样本,鉴别器D 则是去辨别G 生成样本的真假。
如图1 所示,每次判断的结果都会再次作为反向传播的输入,反馈到G、D 中。
生成对抗网络的原理是博弈论,生成器G 是一个由多层感知器表示的可微函数,鉴别器D 是与G对抗的多层感知器,在反复地生成和鉴别中,不断提高两者的能力,最终达到优化两者性能的目的。

图1 GAN 的基本结构
D 和G 的对抗公式为:
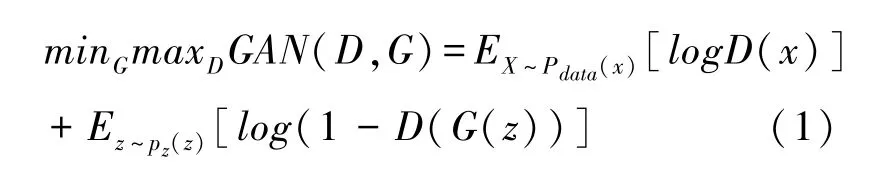
Pdata(x) 代表真实图片集的分布,x是一张真实图片,可以将其视作一个向量。
G 输入的是服从分布z~uniform(0,1) 中的值,使用G 将z1,z2,...,zM映射到x1,x2,...,xM。
鉴别器以x为输入,然后输出x属于Pdata的可能性。
设鉴别器D1 和D2 共享参数,D1 是以x~Pdata中单个的样例为输入,优化时使其最大化;
D2 的输入是x′(G 生成的伪数据),优化时使其最小化。
优化函数为:
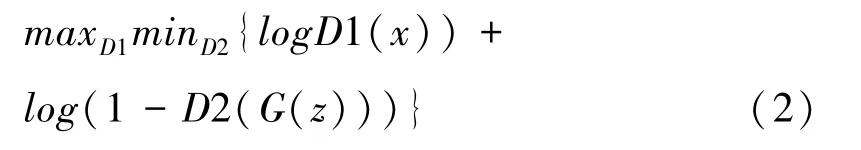
1.2 Flask
Flask 是一个轻量级的开发工具[8],它自身并不包含太多辅助工具,可视作内核,所以其他功能都要通过调用第三方工具库来实现。
并且,Flask 没有自带数据库,可以用MySQL 进行数据库的支持。
Flask 的两个核心应用是Werkzeug和 Jinja2[9]。
作为 WSGI 的一个工具包,Werkzeug 的底层由HTTPServer 实现,用于向开发者提供网络服务器;
Jinja2 是一个模板引擎,相比于其他模板具有更灵活、高性能的优势。Flask 框架流程如图2 所示。

图2 Flask 流程图
所有Flask 程序必须有一个程序实例。
通过该实例,用户可以提交所有在客户端上的请求,通过Werkzeug 进行路由转发,找到相应的视图函数,并获取数据传入Jinja2 模块进行响应,最后再由Flask 返回。
1.3 Android Studio
Android Studio 是Google 开发的IDE[10],它以Java 和kotlin 两种语言为基础,提供编译环境、多种开发工具、安卓系统API 和可视化界面,能够让用户迅速、高效、便捷地开发安卓应用程序。
每个安卓项目都包含多个模块,如应用模块、库模块等。
GradleScripts 下包含了所有的构建文件,在build.gradle 中添加依赖可以自动下载相关的包;
APP 应用模块下主要是:manifests(描述项目配置)、java(实现函数功能)、res(存放图片、文字、布局等资源)。
Android 平台如图3 所示,自底向上地由这四个层次组成:Linux 内核层、运行时库和其他库层、应用框架层、应用程序层[12]。
Android 的优势在于向下既包括操作系统内核,向上又拥有现成的应用软件,并且开源免费,可以直接使用JAVA 语言,对开发人员非常便利[11],并且有非常丰富的图形系统[13]。

图3 Android 平台的架构
2.1 图像生成领域的GAN
只有比较了在图像生成领域中不同GAN 的性能和生成效果,从中选择最佳网络来进行自己的数据训练,才能得到最佳的效果。
目前比较成熟的GAN 技术有DCGAN、CGGAN、CycleGAN、StyleGAN 等,其生成效果如图4 所示。

图4 不同GAN 生成图像的效果
Deep Convolutional 即神经卷积, 是DCGAN[5]中重要的一环,其在生成器与鉴别器特征的提取方面,替代了原始GAN 层面中的多层感知机制。
DCGAN 去除了神经网络中的所有池化层来使整个网络可微,利用批标准化(Batch Normalization)提高网络的稳定性,并以全局池化层代替全连接层来减轻计算量。
DCGAN 属于GAN 基础模型的进化版本。
CGGAN[6]沿用了原始GAN 的多层感知机,但是在原始GAN 的噪声分布和参考标准的分布上,将额外的条件信息y 预先输送到鉴别模型和生成模型,以此作为输入层的一部分,使其生成满足特定要求的样本。
其对抗公式为:

CycleGAN[7]能够将一类图像自动转换到另一类图像,而不要求具有配对的训练集。
其网络结构包含两个生成网络和两个鉴别网络,以此避免映射过于单一。
在原始GAN 的损失函数基础上进行了一个反复的逆向模型训练,损失函数也是在原始GAN 上增加了逆向操作,可以使用不成对的数据进行多次训练,得到通用性更强的模型。
CoGAN[16]同样包括了两个生成网络和两个鉴别网络,利用网络间权值共享不仅节省了内存,而且使得CoGAN 能够可以学习两个域的联合分布,生成跨域样本。
PGGAN[17]随着训练的改善,逐渐向生成器和鉴别器网络中添加层,以此增加图片的空间分辨率,生成大小达到1024×1024 的高分辨率图像,这种方法提高了训练的稳定性。
2018 年NVIDIA 提出了StyleGAN[3],它不仅能生成高分辨率图,细节真实性优于其他GAN 模型。
在图像生成领域NVIDIA 研发的StyleGAN是目前最受认可、应用最为广泛的图像生成方法,因此详细比较了原始GAN 和StyleGAN 一代和二代差别。
2.2 StyleGAN 和原始GAN 的比较
StyleGAN 中“Style”是指数据集中人脸的主要特征,例如人脸的表情、肤色、发型、发色等信息,其网映射网络和图像生成网络如图5 所示。
映射网络F 的目的是将隐变量z进行仿射变换得到中间隐变量w,并用它来控制生成图像的风格。
数据都是有特征的,只有通过对数据的特征进行提取和表示,才能更好地对数据进行分类和生成。
图像数据的特征非常复杂且相互关联,高度耦合的特征影响了模型的分辨能力。
为了将特征充分解耦,探索其深层的特征关系,StyleGAN 将隐变量z映射到一个中间隐空间W。
StyleGAN 将w转换成风格y= (ys,yb), 引入AdaIN (Adaptive Instance Normalization)风格变换方法:

其中,xi表示每个特征图。
图像生成网络G 用于生成图像。
其中,A由中间隐变量w通过仿射变换得到,用于控制生成图像的风格;
B 是随机噪声,用于丰富生成图像的细节。
将A、B 加入到每层的子网络中,可使每个卷积层都根据输入的A 来调整风格。从图5 可以看出,与原始GAN 网络最大的不同在于,原始GAN 的输入是隐变量z或者随机数,而StyleGAN 的输入是一个4×4×512 大小的常数张量和加入每层的子网络的中间隐变量w。

图5 原始GAN 和StyleGAN 的网络结构
StyleGAN 利用渐进式增长(Progressive Growth)[3],先训练一个小分辨率的图像,稳定训练当前分辨率,之后再逐步过渡到更高分辨率的图像。
这样虽然能得到分辨率较高的细节,但却不能很好地进行移动变化。
另外,StyleGAN 生成的图片存在瑕疵,一些生成图出现了明显的伪影。
2.3 StyleGAN 和StyleGAN2 的比较
针对StyleGAN 存在的问题,NVIDIA 耗时一年做出了完善和改进,推出了StyleGAN2[4]。
如图6 所示,在StyleGAN2 的网络中去除了AdaIN 操作,来达到去除生成图像中伪影的目的,还加入了Weight Demodulation 算法对风格融合进行特定量级控制,用Mod std 算法来进行卷积层权重的缩放:
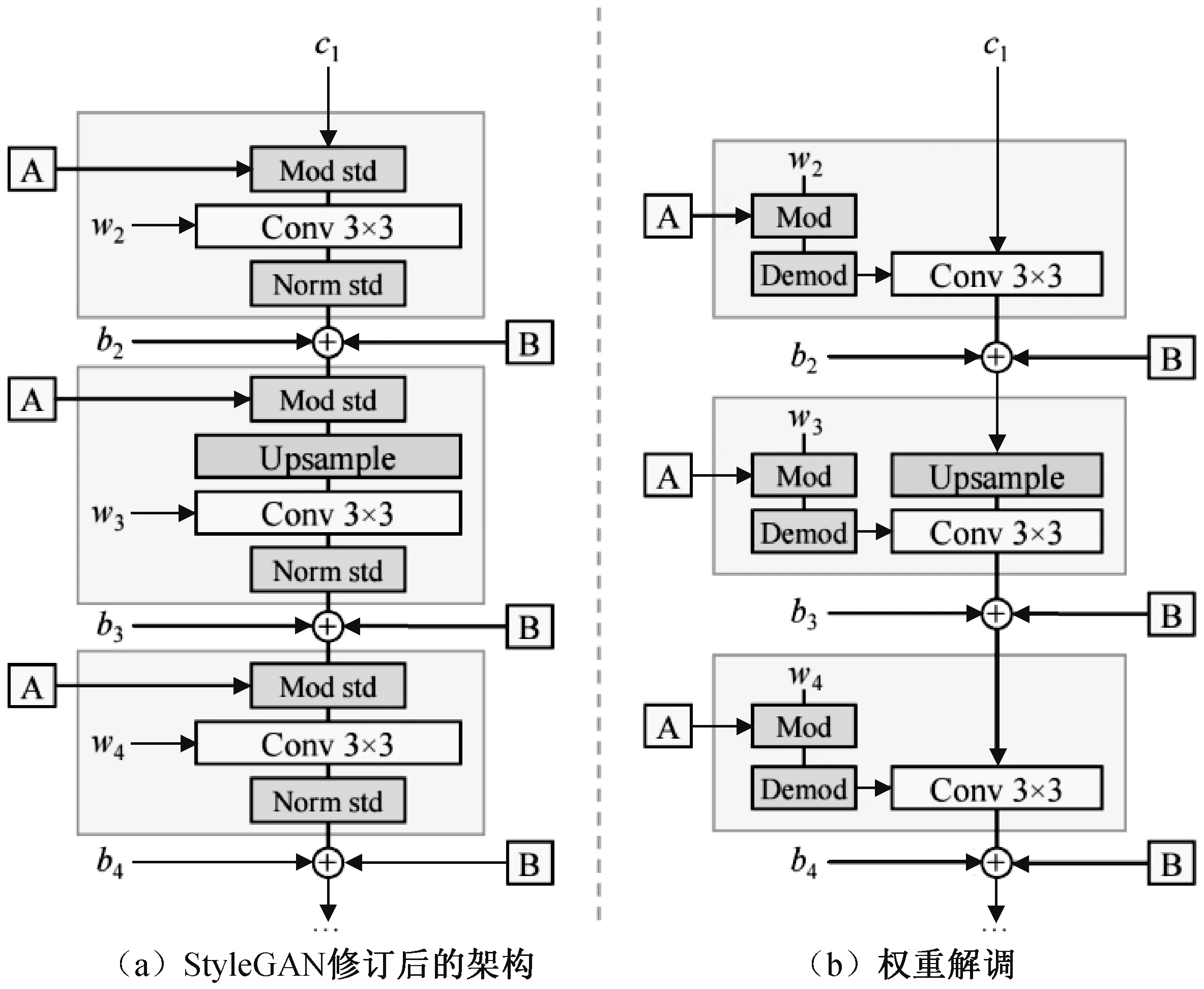
图6 StyleGAN2 结构

接着对卷积层的权重进行Demod:

那么,得到新的卷积层权重为:
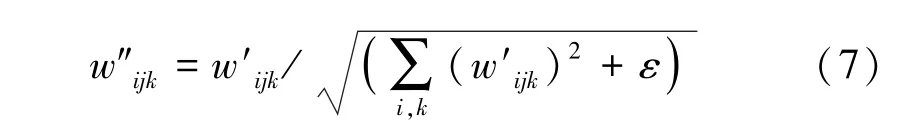
其中,加一个数值非常小的ε,是为了避免分母为0 的情况发生,以此保证该公式数值的稳定性。
同时,StyleGAN2 中引入了延迟正则化(Lazy Regularization)算法和路径长度正则化(Path Length Regularization)算法。
只有当数据分布偏离预期时,才使用R1 regularization。
路径长度正则化使隐空间的插值变得更加平滑和线性,即在对隐变量进行变化操作时,让这种变化等比例反映到图像中去,使其具有相同的变化幅度,如图7 所示。

图7 等幅度变化对比
StyleGAN2 在性能和生成图片质量方面都达到了顶尖水平,因此选择StyleGAN2 作为本文在图片训练和生成方面的使用技术。
3.1 数据集处理
目前,人脸图像生成系统的实现基本都是利用了欧美人脸数据集训练模型。
为了满足实际应用需要,本文收集了来自互联网的五千多张日式大头贴制作数据集,并且利用现有技术对这些日本人脸大头贴进行了背景分割和妆容迁移,所有人像单独切割出来,背景设置为白色,共有5861 张样本,如图8 所示。

图8 日式大头贴数据集
为了丰富软件的功能,满足用户的个性化需求,本文使用FFHQ[2]、亚洲人脸数据集、日式大头贴数据集来训练模型,利用python 自带的图像转换函数img.resize()对图片进行剪裁,再用img.convert()把四维图片转三维图,最终裁出全部是512 *512 规格的RGB 图,然后将数据集转为tfrecords 格式的多分辨率文件。
理论上tfrecords 是一种可以保存任何信息的二进制文件格式,本文用该格式来存储所有的数据集信息。
3.2 模型训练
模型训练在64 位的ubuntu 系统上进行,使用了一张24G 的TITAN(GPU),在经过数次迭代后得到相应*.pkl 文件,即通过训练对应产生的生成模型,以日式大头贴为例,生成虚拟人像的效果如图9。

图9 生成的虚拟人像
为了在接下来的工作中生成满足实际需求的虚拟人像,执行生成图片命令时要设置恰当的参数, 其中 seeds 控制生成图像的数量,truncation-psi 控制图像的风格差异,取值范围为[0,1]。
从图10 中可以看出,取值趋于0 时图像差异最小,背景和人像的色彩和动作单一,连续生成的图像几乎是一个模子刻出,变化小,但人脸逼真度高;
取值为1 时差异最大,面部表情、动作、背景、色彩非常丰富多变,但有时候会出现拟合过度问题,出现虚假且恐怖的人像场景图。本文通过生成大量不同图片、对比数据,得出结论:truncation-psi 取中间值0.5 左右效果最佳。

图10 truncation-psi 不同取值生成的虚拟人像
3.3 Flask 服务器部署
首先,使用Flask 来提供接口,设置服务器ip 并定义端口号为:8081。
然后,在run_server.py 文件中定义三个网页来分别调用不同的模型获取图像,例如:

其中load_model, get_img 是本文自定义写在run_service.py 文件中的接口函数,Gs 是加载的模型变量,Gs_kwargs 是初始化的一个字典。连接服务器,激活环境,运行run_server.py 文件就能从网页上读取到随机生成的虚拟人像图片,服务器端做出响应,如图11 所示。

图11 服务器端响应
为测试不同模型的性能,每个模型在同一测试点使用相同的输入,生成单张虚拟图片,服务器端各个模型生成图片的时间如图12 所示,单张图片的生成时间均小于0.2ms,满足实际的应用需求。
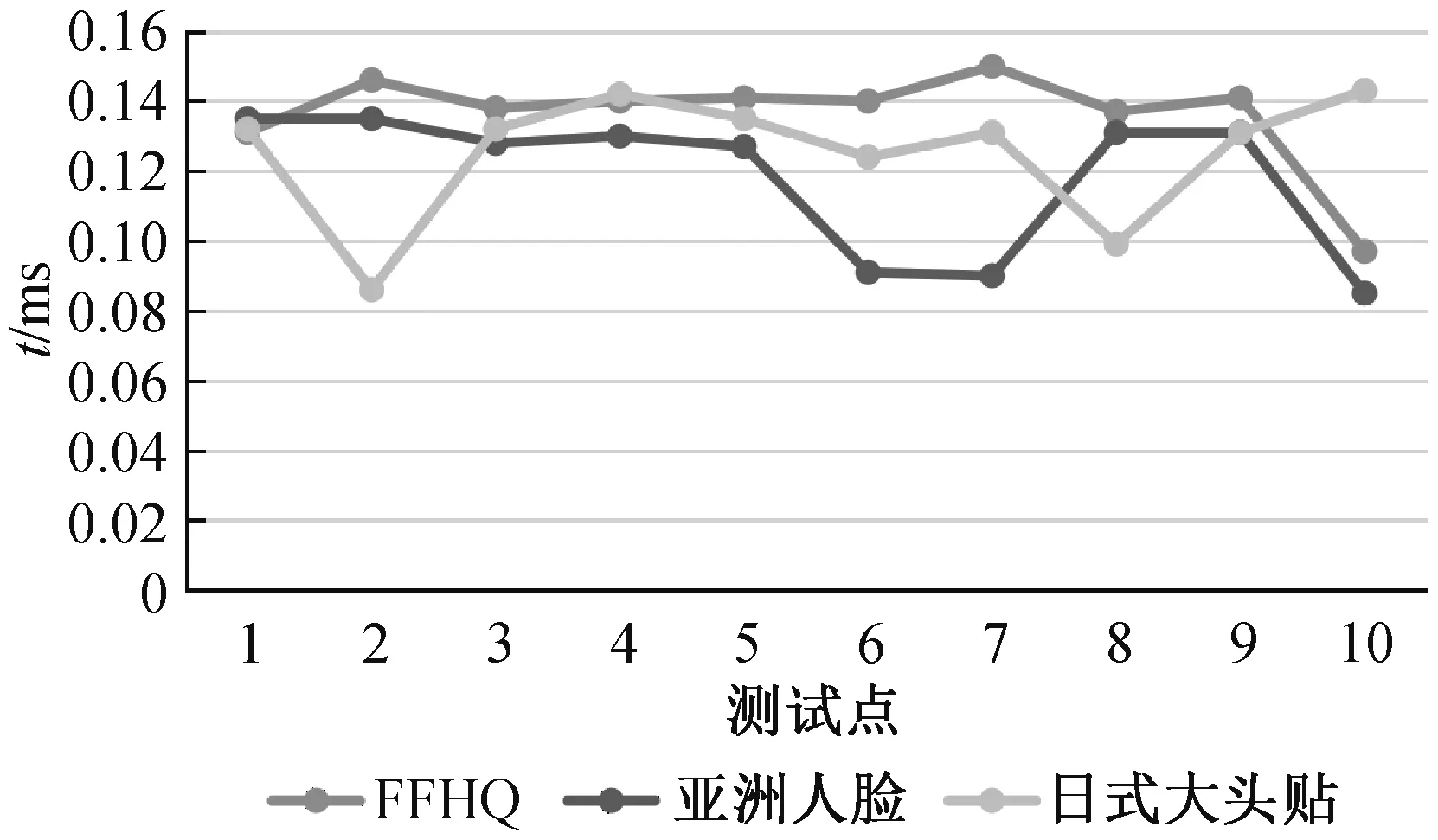
图12 模型生成图片的时间
3.4 安卓平台软件开发
3.4.1 环境配置
首先安装Android Studio 工作环境,在gradle文件中添加OKhttp 等各种需要用到的依赖,点击syn now 后会自动将需要的包入库。
3.4.2 功能设计与实现
在主界面中点击设置好的Button,就会跳转到button 界面。
并且在主界面中想要退出该软件,必须连续按下两次返回键才会终止进程,防止用户出现误按退出的情况。
具体实现方法:button 跳转是利用Intent 新建事件实现。
两次按键才能返回的实现是利用 System.currentTimeMillis()函数记录当前系统的时间,将两次按键时间差与设定的数值作对比,小于则返回,大于的话正常继续进程。
在button 跳转界面中,可以点击选择生成不同种族和风格的人物图像,并且可以对生成的图进行保存。
对于生成图片的Button 按钮,是通过点击事件后利用OKhttp 协议发送网络请求,在服务器端生成加载图片后返回显示在手机的ImageView 中实现的。
其中第一个是要涉及APP 的用网权限,需要AndroidManifest.xml 文件中加上用网许可。
第二个是要涉及到图片的格式转换,需要转换成Bitmap 进行中间数据流传输。
同时为了避免出现多个按钮同时按下,服务器应答不过来的情况,本文在这里专门做了限制处理,在一个按钮按下后,必须等待请求结束、返回图片,或者强行终止进程,才能恢复其他Button 的使用权,否则在请求过程中,所有Button 按键均无效。
Button 的使用调用了setEnabled()函数。
在请求过程中设置progressbar 来提示加载过程,当图片尚未加载出来,progressbar 会一直转动,并会有提示信息在最下面显示:“模型加载中,请稍后”,加载完成后progressbar 会自动消失。
progressbar 的显示调用了setVisibility( )函数。
安卓对targetSdkVersion 版本在26 以上的软件开发加强了对SD 卡或本机读取、改写权限的限制。
因此除了在AndroidManifest.xml 文件中加上静态的读写权限外,还需要在APP 中动态申请存储权限。
保存图片时,先要对系统进行一次扫描,看该软件图片保存的指定路径是否存在,如果存在,直接保存进指定文件夹即可,否则创建新文件夹。
保存过程中也要对图片进行数据流转换。
保存成功或因为保存中有一步骤出错致使图片未能保存成功,都会有相应的提示信息出现。
提示信息用Toast.makeText().show()函数即可实现。
本软件开发的默认语言是英语,为了适应实际需要,APP 需具有本地化的功能。
如图13 所示,利用string.xml 文件,对应写了汉语和英语的翻译,软件语言根据用户手机系统语言自动切换。
图13 本地化之中英文参照
3.4.3 界面设计
主界面运用了 ImageView、 TextView 和Button 的控件,设置ImageView 显示的图片并选择对应和谐的Button 框架颜色、TextView 字体颜色,添加guideline 规范三个控件的空间位置。在跳转后的button 界面中,添加了两个Image-View,其中一个选取了一张拼接的人脸生成图作为初始化图片,另一个用于显示底边花纹。
软件添加多个Button 控件对应不同功能,挑选四种颜色将Button 依次排列,同样利用了guideline来规范控件的空间位置。
最后,添加progressbar作为加载图片时的动态提示。
图14 跳转后页面设计图
3.4.4 软件展示
进入软件的首页面展示如图15。
点击生成按钮进入虚拟人像的生成环节,用户可以选择生成亚洲人脸、日本女孩或欧洲人脸,模型加载进程提示如图16 所示。

图15 中英文对照版本的主界面

图16 中英文对照版本的图片加载界面
在生成图像后点击保存图片的按钮会自动申请系统权限,如图17 所示。
禁止后无法保存照片,但在下一次按下保存键后,会再次出现该提示信息。

图17 生成图片并申请权限
本文收集并制作了包含5861 张人脸图像的日式大头贴数据集,对比了多种生成对抗网络,最后确定利用StyleGAN2 来训练数据集,生成相应的神经网络模型。
同时,利用Flask 实现服务器上服务端的部署,一共有三个模型,分别是本文训练的日式大头贴风格模型、亚洲人脸数据模型、以及StyleGAN2 项目开源的FFHQ 训练模型。
利用Android Studio 实现客户端开发,利用Flask 提供的接口收取图片,实现了在安卓手机APP 上的人机交互,能够生成日式大头贴、亚洲人脸和欧美人脸图像,开发了基于生成对抗网络的虚拟人像生成软件,有助于避免图像应用中侵犯肖像权的问题,满足了实际生活中不同场景下的个性化需求。
猜你喜欢 日式人脸图像 玻璃窗上的人脸奥秘(2021年5期)2021-06-15A、B两点漂流记初中生世界·九年级(2018年12期)2018-12-22智力考场:有趣的图片测试小雪花·初中高分作文(2017年9期)2018-05-21“日式脸型”也能打造时尚感的妆容米娜·女性大世界(2016年11期)2016-12-23“领家系”可爱脸VS“高冷系”美人脸米娜·女性大世界(2016年8期)2016-08-17瀛海饮魂 匠心之作BOSS食尚(2016年4期)2016-04-01名人语录的极简图像表达读者(2015年9期)2015-05-04长得象人脸的十种动物奇闻怪事(2014年5期)2014-05-13一次函数图像与性质的重难点讲析初中生世界·八年级(2014年2期)2014-03-15趣味数独等4则意林(2011年10期)2011-05-14